Some notes taken when reading hello interview.
Content
- API Gateway
- Delivery Framework
- Core Concepts
- Key Technologies
- Common Patterns
- Core Concepts (In Depth)
- Key Technologies (In Depth)
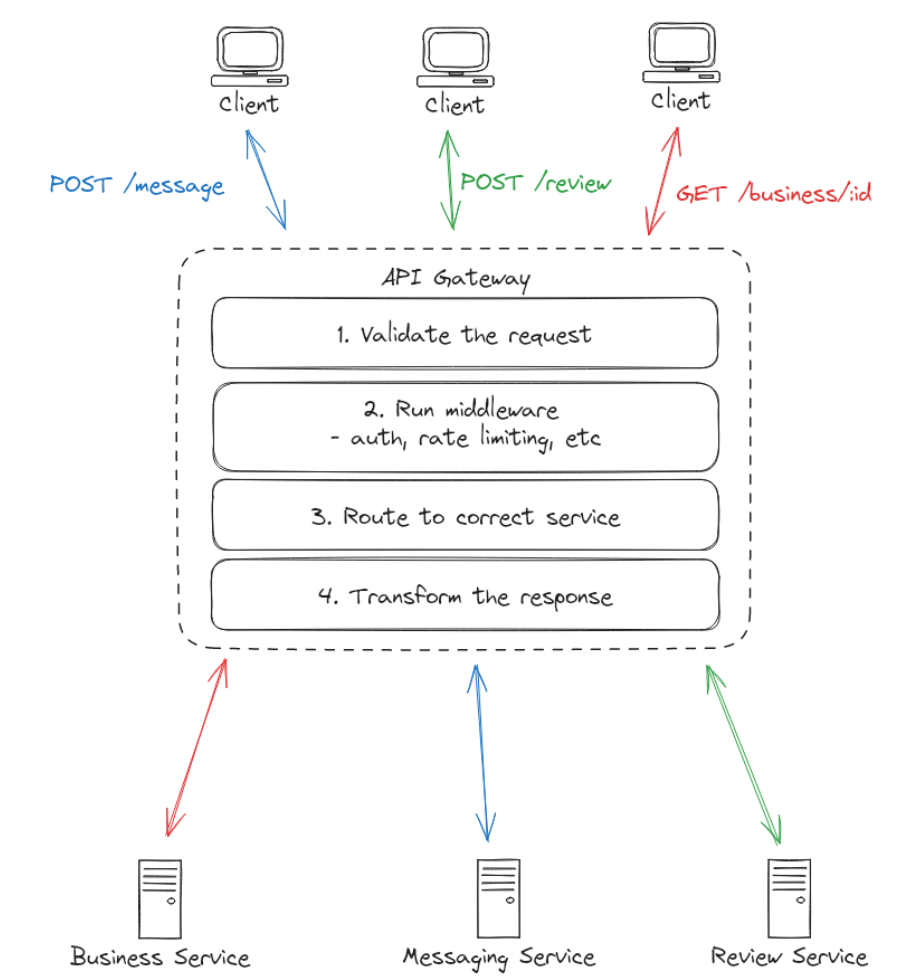
API Gateway
An API Gateway serves as a single entry point for all client requests, managing and routing them to appropriate backnd services. An API Gateway manages centralized middleware like authentication, routing, and request handling.
The gateway’s primary function is request routing - determining which backend service should handle each incoming request. Nowadays, API gateways are also used to handle cross-cutting concerns or middleware like authentication, rate limiting, caching, SSL termination, and more.
Request flow
- Request validation
- API Gateway applies middleware (auth, rate limiting, etc.)
- API Gateway routes the request to the appropriate backend service
- Backend service processes the request and returns a response
- API Gateway transforms the response and returns it to the client
- Optionally cache the response to future requests
Request Validation
The API Gateway checks if incoming requests are properly formatted and contain all the required information. The validation includes checking that the request URL is valid, required headers are present, and the request body matches the expected format.
Middleware
Several middleware tasks
- Authenticate requests using JWT tokens
- Limit request rates to prevent abuse
- Terminate SSL connections
- Log and monitor traffic
- Compress responses
- Handle CORS headers
- Whitelist/blacklist IPs
- Validate request sizes
- Handle response timeouts
- Version APIs
- Throttle traffic
- Integrate with service discovery
Routing
Layer 4 (IP based, TCP/IP layer) and layer 7 (http layer, request based, URL, HTTP method, query parameters, request headers)
Backend Communication
The gateway can transform the request into the appropriate protocol before sending it to the backend service.
Response Transformation
The gateway can transform the response into the format requested by the client.
Example:
1 | // Client sends a HTTP GET request |
Caching
The API Gateway can implement various caching strategies:
- Full Response Caching: Cache entire responses for frequently accessed endpoints
- Partial Caching: Cache specific parts of responses that change infrequently
- Cache Invalidation: Use TTL or event-based invalidation
Horizontal Scaling
API Gateways are typically stateless, which is ideal for horizontal scaling
Delivery Framework
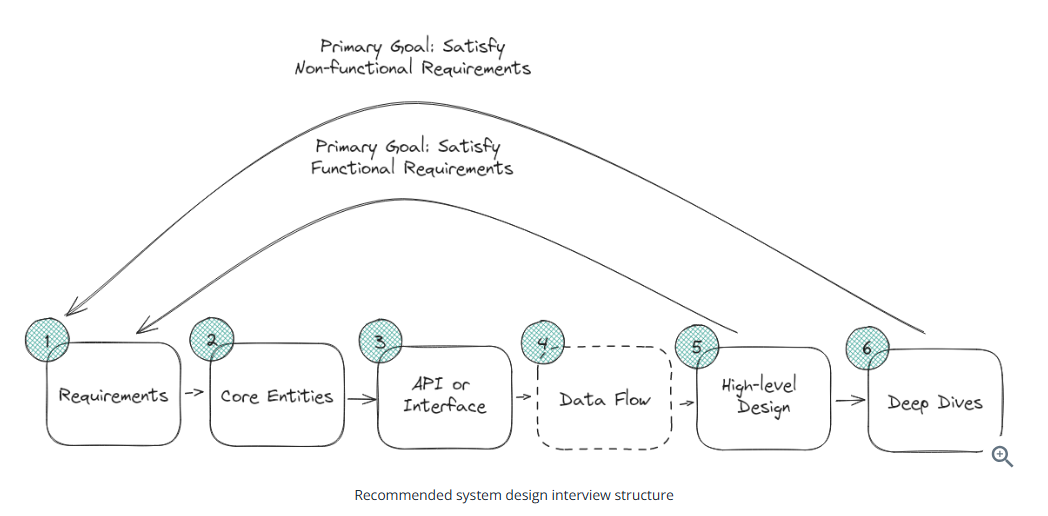
Requirements (5 mins):
- functional requirements: users/clients should be able to… We should identify and priotize the top 3
- non-functional requirements: the system should be able to
- CAP theorem: consistency or availability
- environment constraints: mobile device or not, limited memory/bandwidth or not
- scalability: bursty traffic? read write ratio?
- latency: how quickly does the system need to respond to user requests
- durability: can data be lost or not
- security: how secure does the system need to be
- fault tolerance: how well does the system need to handle failures, redundancy, failover, recovery mechanisms
- compliance: legal or regulatory requirements
Core Entities (2 mins):
In the Twitter example, core entities are:
- User
- Tweet
- Follow
API or System Interface (5 mins):
- RESTful API: uses HTTP verbs
- GraphQL API: allows clients to specify exactly what data they want to receive from the server
- Wire Protocol: when communicating over websockets or raw TCP sockets
For Twitter, REST endpoints:
1 | POST /v1/tweet |
[Optional] Data Flow (5 mins):
For a web crawler:
- Fetch seed URLs
- Parse HTML
- Extract URLs
- Store data
- Repeat
High Level Design (10-15 mins):
Design an architecture that satisfies the designed API and the identified requirements
Deep Dives (10 mins)
- Make sure to meet all non-functional requirements
- Adress edge cases
- Identify and address issues and bottlenecks and improve the dedsign based on probes from the interviewer
Core Concepts
Scaling
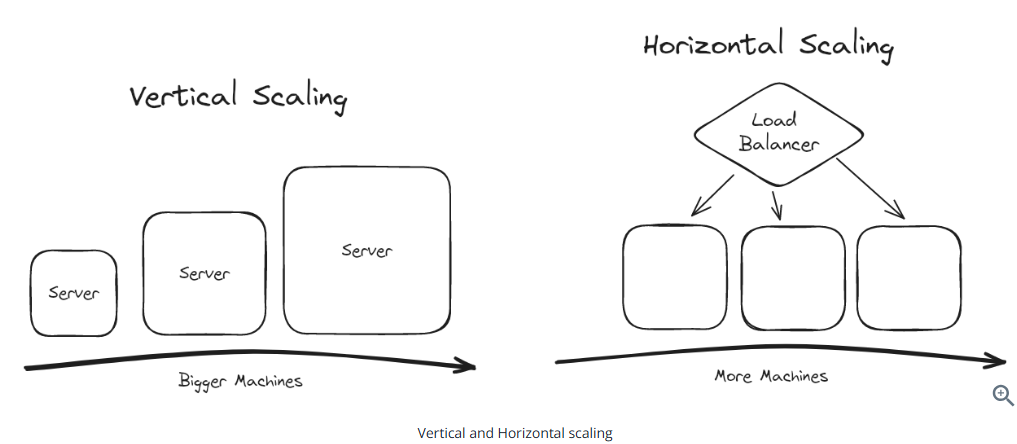
Vertical scaling is less difficult than horzontal scaling
Work distribution:
- Load balancing
- Introducing a queusing system (task dispatcher)
Horizontal scaing on data introduces synchronization challenges
CAP: availability should be the default choice. Strong consistencyis needed wher ereading stale data is unacceptable.
Examples of systems that require strong consistency:
- Inventory management systems
- Booking systems for limited resources
- Banking systems
Locking
- Granularity of the lock: we want locks to be as fine-grained as possible
- Duration of the lock: we want locks to be held for as short a time as possible
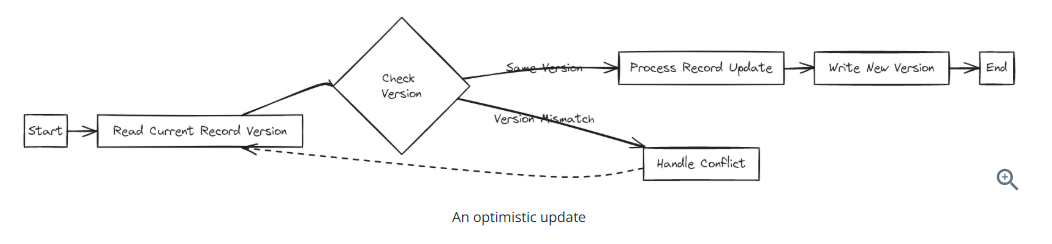
Optimistic concurrency control (lock-free and we can also use this strategy in our own system). It’s should be used only under the assumption that most of the time we won’t have contention (multiple people trying to lock at the same time)
Indexing
Indexing is the process of creating a data structure that makes reads faster
The most basic method of indexing is using a hash map. Another way is using a sorted list, allowing us to do binay search to find the data we need in O(log n) time
Specialized indexes:
- geospatial indexes: used to index location data, find the nearest restaurant or the nearest gas station. Postgres has a PostGIS extension
- vector databases: used to index high-dimensional data, find similar images or similar documents
- full-text indexes: used to index text data, search for documents or search for tweets. ElasticSearch. CDC: ES cluster is listening to changes coming from the database and updating its indexes accordingly
Communication Protocols
- HTTP(S): simple request and response model, stateless
- SSE: server sent events, similar to long polling, but more efficient for undirectional communication from the server to the client. SSE allows the server to push updates to the client wenever new data is available, without the client having to make repeated requests as in long polling. This is achived through a single, long-lived HTTP connection. SSE is simpler than Websockets and does not need special handling like maintaining the stateful connections between server and client
- long polling: near-realtime updates, the client makes a request to the server and the server holds the request open until it has new data to send to the client. Once the data is sent, the clientt makes another request and the process repeats
- Websockets: realtime, bidirectional communication between the client and the server. A common pattern is to use a message broker to handle the communication between the client and the server and for the backend services to communicate with this message broker. Stateful
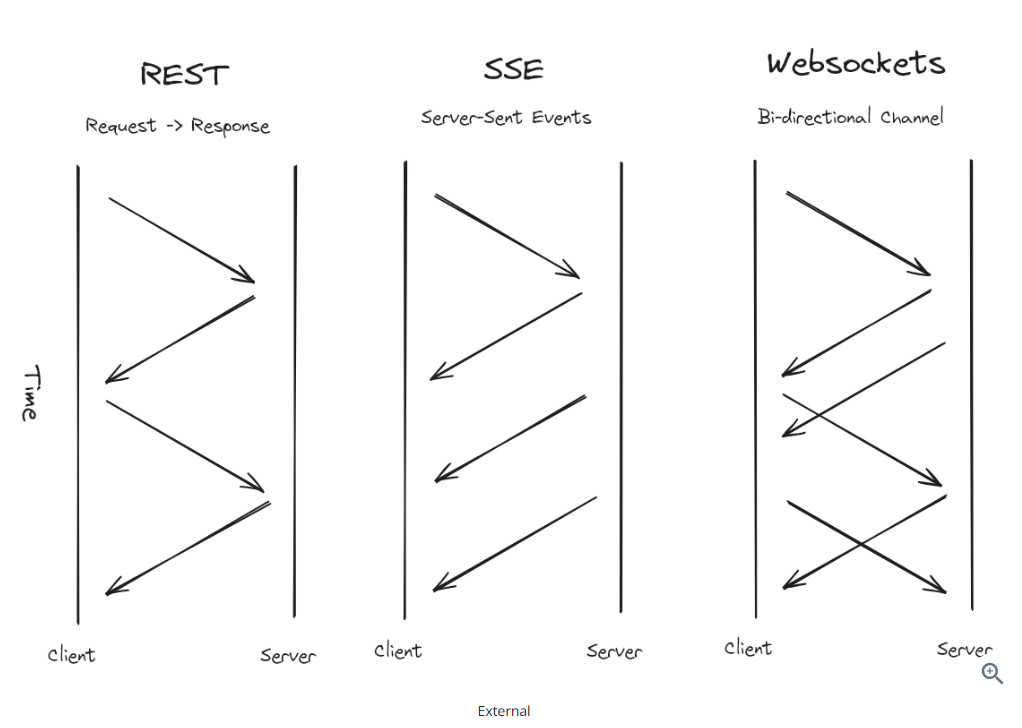
States can be maintained in a message broker or a database. Stateless services can easily scale horizontally.
Security
- Authentication/Authorization: It’s often sufficient to say “My API Gatewa will handle authentication and authorization”
- Encryption: protocol encryption, TLS/SSL
- Data Protection: authorization, rate limiting, request throttling
Monitoring
- Infrastructure monitoring: the process of monitoring the health and performance of the infrastructure, including CPU usage, memory usage, disk usage, and network usage. Datadog or New Relic
- Service-level monitoring: the process of monitoring the health and performance of the service, including request latency, error rates, and throughput
- Application-level monitoring: the process of monitoring the health and performance of the application, including things like the number of users, the number of active sessions, and the number of active connections
Key Technologies
Core Database
phrase: “I’m using Postgres here because its ACID properties will allow me to maintain data integrity.”
Relational Databases: queried using SQL
Useful RDBMS features:
- SQL joins: a way of combining data from multiple tables
- Indexes: a way of storing data in a way that makes it faster to query. Implemented using a B-Tree or a Hash Table
- RDBMS Transactions: a way of grouping operations together into a single atomic operation
The most common RDBMSs are Postgres and MySQL
NoSQL Databases:
- Flexible data models: schemaless
- Handling big data and real-time web apps: unstructured, large volumes of data, real-time processing and analytics
- Consistency models: various consistency ranging from strong to eventual consistency
- Indexing: make data faster to query. The most common types of indexes are B-Tree and Hash Table indexes
- Scalability: NoSQL databases scale horizontally by using consistent hashing and/or sahrding to distribute data across many servers
Common NoSQL databases: DynamoDB, Cassandra, MongoDB
Blob Storage
Blob storage can be used to store large, unstructured blobs of data
Blob storage services: Amazon S3, Google Cloud Storage
Blob storage is more cost effective than a traditional database
Blob storage services often work in conjunction with CDNs
Common examples:
- Design YouTube: store videos in blob storage, store metadata in a database
- Design Instagram: store images & videos in blob storage, store metadata in a database
- Design Dropbox: store files in blob storage, store metadata in a database
A common setup:
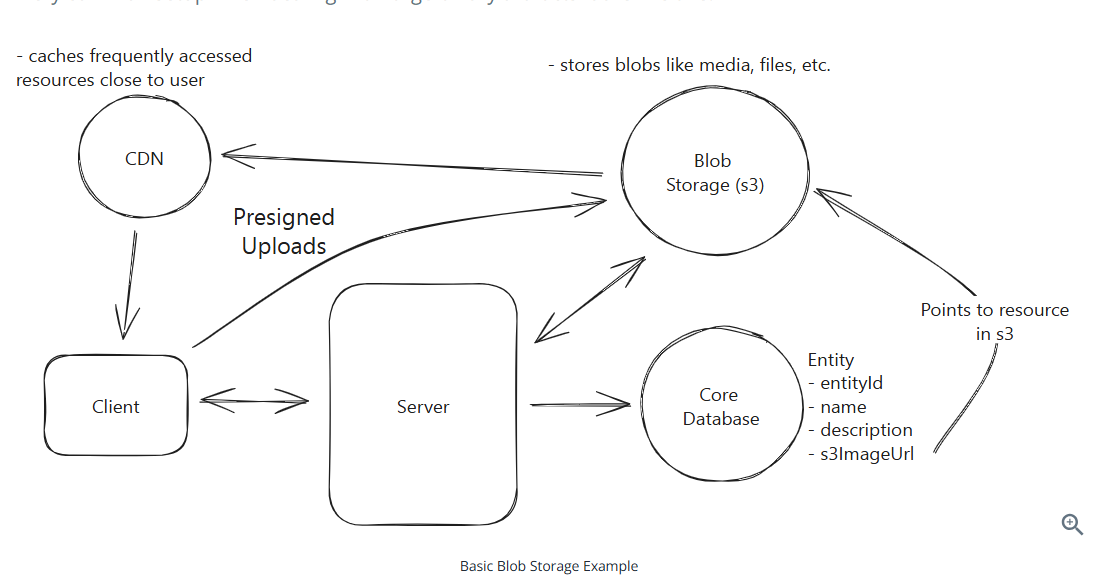
To upload:
- When clients want to upload a file, they request a presigned URL from the server
- The server returns a presigned URL to the client, recording it in the database
- The client uploads the file to the presigned URL
- The blob storage triggers a notification to the server that the upload is complete and the status is updated
To download:
- The client requests a specific file from the server and are returned a presgned URL
- The client uses the presigned URL to download the file via the CDN, which proxies the request to the underlying blob storage
Things abut blob storage:
- Durability: blob storage services are designed to be incredibly durable
- Scalability: hosted blob storage solutions like AWS S3 can be considered infinitely scalable
- Cost: blob storage services are designed to be cost effective
- Security: blob storage services have built-in security features like encryption at rest and in transit
- Upload and Download Directly from the Client: blob storage services allow you to upload and download blobs directly from the client
- Chunking: when uploading large files, it’s common to use chunking to upload the file in smaller pieces
Search Optimized Database
Full-text search is the ability to search through a large amount of text data and find relevant results
Search optimized databases use techniques like indexing, tokenization, and stemming to make search queries fast and efficient. They work by building what are called inverted indexes.
Inverted indexes: a data structure that maps from words to the documents that contain them
A simple example:
1 | { |
Things about search optimized databases:
- Inverted indexes
- Tokenization: the process of breaking a piece of text ino individual words
- Stemming: the process of reducing words to their root form
- Fuzzy Search: the ability to find results that are similar to a given search term
- Scaling: search optimized databases scale by adding more nodes to a cluster and sharding data across those nodes
The leader of search optimized databases is ElasticSearch. It’s a distributed, RESTful search and analytics engine that is built on top of Apache Lucene.
API Gateway
An API gateway is responsible for routing incoming requests to the appropriate backend service.
The gateway is also typically responsible for handling cross-cutting concerns like authentication, rate limiting, and logging.
The most common API gateways:
- AWS API Gateway
- Kong
- Apigee
Load Balancer
A load balancer can distribute traffic across multiple machines to avoid overloading any single machine or creating a hotspot.
The most common decision is whether to use an L4 or L7 load balancer.
Rule of thumb: if you have persistent connections like websockets, you’ll likely need L4 load balancer. Otherwise L7 load balancer.
The most common load balancers:
- AWS Elastic Load Balancer
- Nginx
- HAProxy
- Sometimes specialized hardware load balancer
Queue
Queues serve as buffers for bursty traffic or as a means of distributing work across a system.
Be careful of introducing queues into synchronous workloads. If you have strong latency requirements, by adding a queue you’re nearly guaranteeing you’ll break that latency constraint.
Use cases:
- Buffer for Bursty Traffic: In a ride-sharing application like Uber, queues can be used to manage sudden surges in ride requests. A queue can buffer incoming requests, allowing the system to process them at a manageable rate without overloading the server or degrading the user experience.
- Distribute Work Across a System: In a cloud-based photo processing service, queues can be used to distribute expensive image processing tasks.
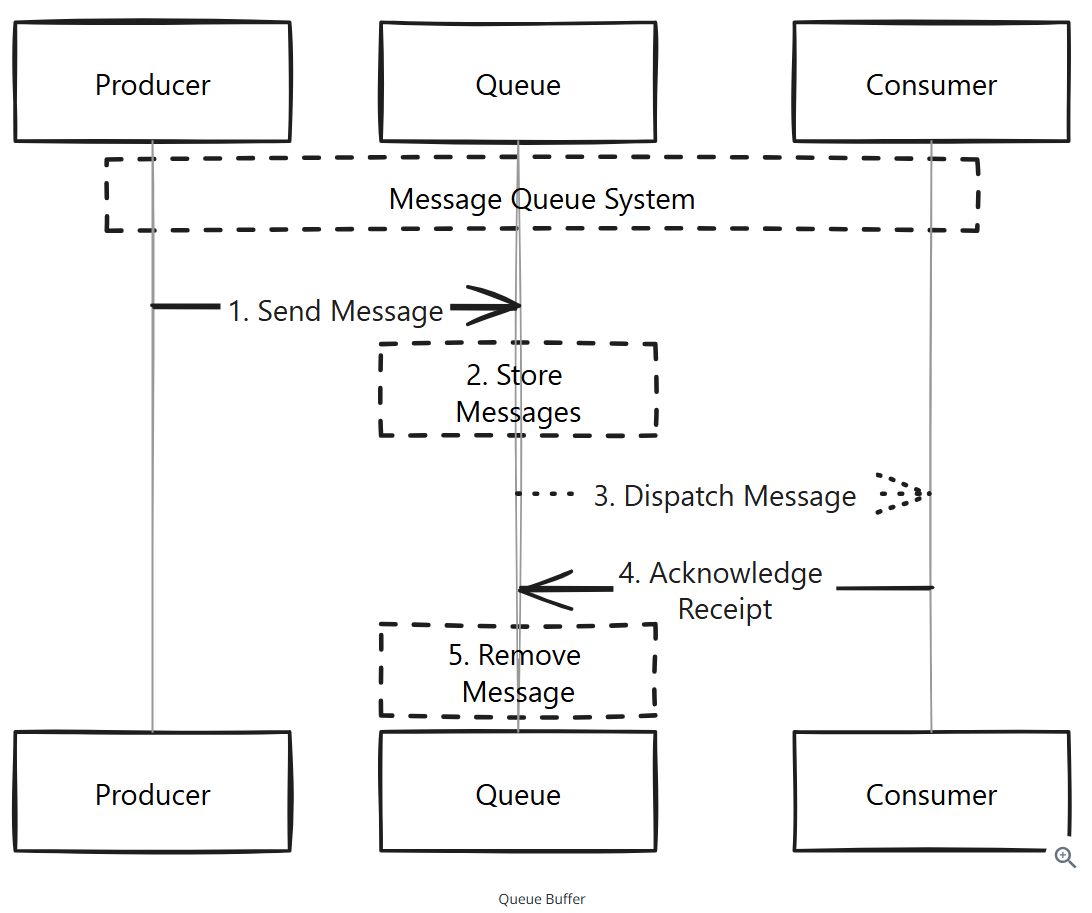
Things about queues:
- Message Ordering: Most queues are FIFO. Some queues like Kafka allow for more complex ordering guarantees, such as ordering based on specified priority or time.
- Retry Mechanisms: Many queues have built-in retry mechanisms that attempt to redeliver a message a certain number of times before considering it a failure. You can configure retries, including the delay between attempts, and the maximum number of attempts.
- Dead Letter Queues: Dead letter queues are used to store messages that cannot be processed. They’re useful for debugging and auditing, as it allows you to inspect messages that failed to be processed and understand why they failed.
- Scaling with Partitions: Queues can be partitioned across multiple servers so they can scale to handle more messages.
- Backpressure: Backpressure is a way of slowing down the production of messages when the queue is overwhelmed. This helps prevent the queue from becoming a bottleneck in your system.
Most common queueing technologies:
- Kafka
- SQS
Streams / Event Sourcing
Event sourcing is a technique where changes in application state are stored as a sequence of events. These events can be replayed to reconstruct the application’s state at any point in time, making it an effective strategy for systems that require a detailed audit trail or the ability to reverse or replay transactions.
Streams can retain data for a configurable period of time. Use cases:
- When you need to process large amounts of data in real-time: for example designing a system for a social media platform where you need to display real-time analytics of user engagemnts (like, comments, shares)
- When you need to support complex processing scenarios like event sourcing: for example designing a banking system with transactions
- When you need to support multiple consumers reading from the same stream: for example designing a real-time chat application. For real-time communicaton. Pub/Sub pattern.
Things about streams:
- Scaling with Partitioning
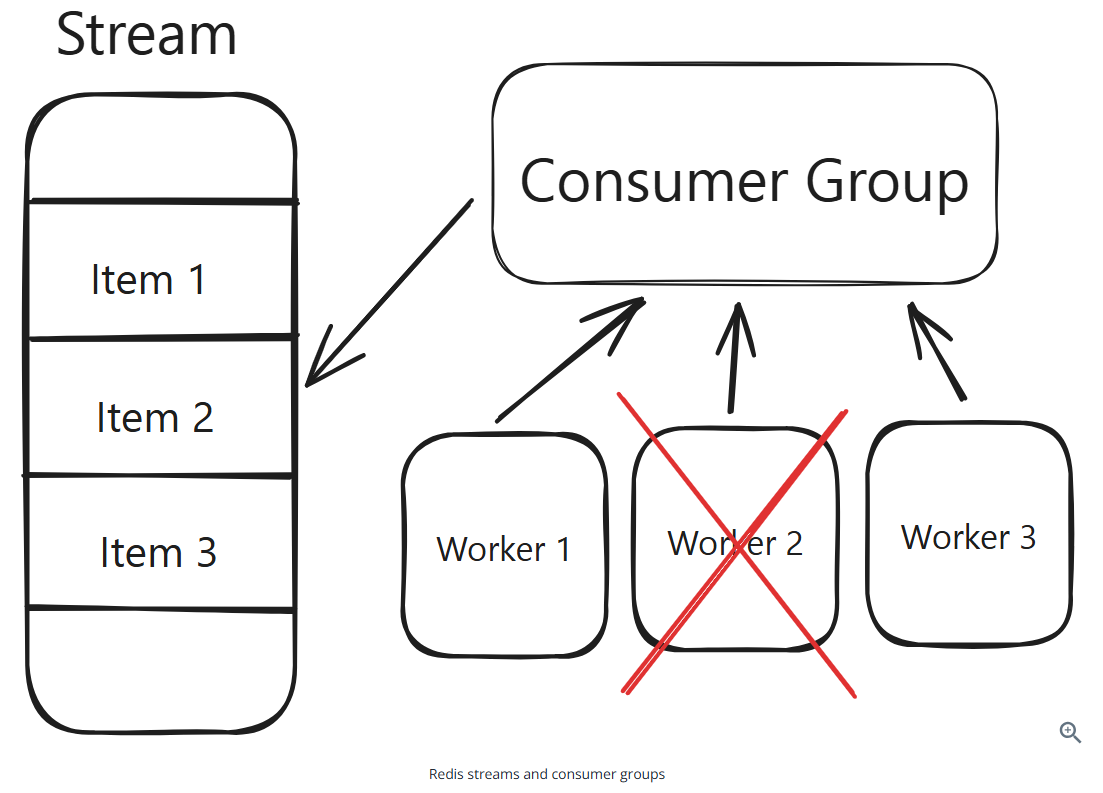
- Multiple Consumer Groups: Streams can support multiple consumer groups, allowing different consumers to read from the same stream independently.
- Replication: Streams can replicate data across multiple servers to support fault tolerance.
- Windowing: Streams can support windowing, which is way of grouping events based on time or count.
The most common streaming technologies:
- Kafka
- Flink
- Kinesis
Distributed Lock
Traditional databases with ACID properties use locks to keep data consistent, but they are not used for longer-term locking. Instead distributed locks come in handy for those use cases.
Distributed locks are used when you need to lock something across different systems or processes for a reasonable period of time. They’re often implemented using a distributed key-value store like Redis or Zookeeper.
Common examples of when to use a distributed lock:
- E-Commerge Checkout system: Use a distributed lock to hold a high-demand item, like limited-edition sneakers, to prevent race condition.
- Ride-Sharing Matchmaking: A distributed lock can be used to manage the assignment of drivers to riders. When a rider requests a ride, the system can lock a nearby driver, preventing them from being matched with multiple riders simultaneously.
- Distributed Cron Jobs: For system that run scheduled tasks (cron jobs) across multiple servers, a distributed lock ensures that a task is executed by only one server at a time.
- Online Auction Bidding System: In an online auction, a distributed lock can be used during the final moments of bidding to ensure that when a bid is placed in the last seconds, the system locks the item briefly to process the bid and update the current highest bid.
Things about distributed locks:
- Locking Mechanisms: There are different ways to implement distributed locks. One cmmon implementation uses Redis is called Redlock.
- Lock Expiry: Distributed locks can be set to expire after a certain amount of time. This is important to ensure locks don’t get stuck in a locked state if a process crashes or is killed.
- Locking Granularity: Distributed locks can be used to lock a single resource or a group of resources.
- Deadlocks: Deadlocks can occur when two or more processes are waiting for each other to release a lock.
Distributed Cache
A cache is just a server, or a cluster of servers, that stores data in memory.
Use cases:
- Save Aggregated Metrics: cache can used be to store metrics that is expensive to compute
- Reduce Number of DB Queries: store user session data in cache for faster login
- Speed Up Expensive Queries: cache SQL query results
Things about distributed cache
- Eviction Policy
- LRU: Evicts the least recently accessed items first
- FIFO: Evicts items in the order they were added
- LFU: Removes items that are least frequently accessed
- Cache Invalidation Strategy: This is the strategy used to ensure the data in cache is up to date.
- Cache Write Strategy: This is the strategy used to make sure the data written to cache is consistent. Some strategies:
- Write-Through Cache: Writes data to both the cache and the underlying datastore simultaneously. Ensures consistency but can be slower for write operations.
- Write-Around Cache: Writes data directly to the datastore, bypassing the cache. This can minimize cache pollution but might increase data fetch times on subsequent reads.
- Write-Back Cache: Writes data to the cache and then asynchronously writes the data to the datastore. This can be faster for write operations but can lead to data loss if the cache is not persisted to disk.
The two most common in-memory caches are:
- Redis
- Memcached
CDN
A content delivery network (CDN) is a type of cache that uses distributed servers to deliver contents to users based on their geographic location. CDNs are often used to deliver static content like images, videos, and HTML files, they can also be used to deliver dynamic content like API responses.
CDNs work by caching content on servers that are close to users. When a user requests content, the CDN routes the request to the closest server. If the content is cached on that server, the CDN will return the cached content. If the content is not cached on that server, the CDN will fetch the content from the origin server, cache it on the server, and then return the content to the user.
Things about CDNs:
- CDNs are not just for static assets: a blog post that is updated once a day can be cached by a CDN
- CDNs can be used to cache API responses: can improve performance of APIs
- Eviction policies: TTL or cache invalidation mechanisms
Examples of CDNs
- Cloudflare
- Akamai
- Amazon CloudFront
Common Patterns
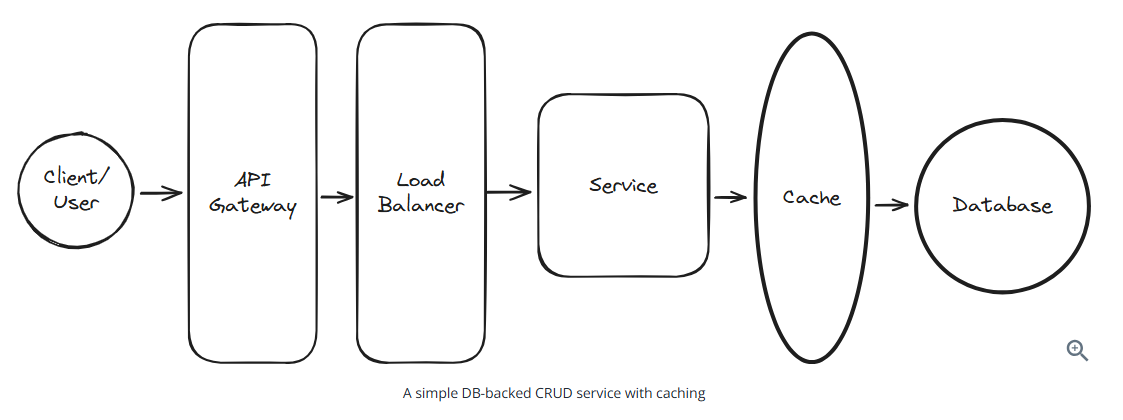
Simple DB-backed CRUD service with caching
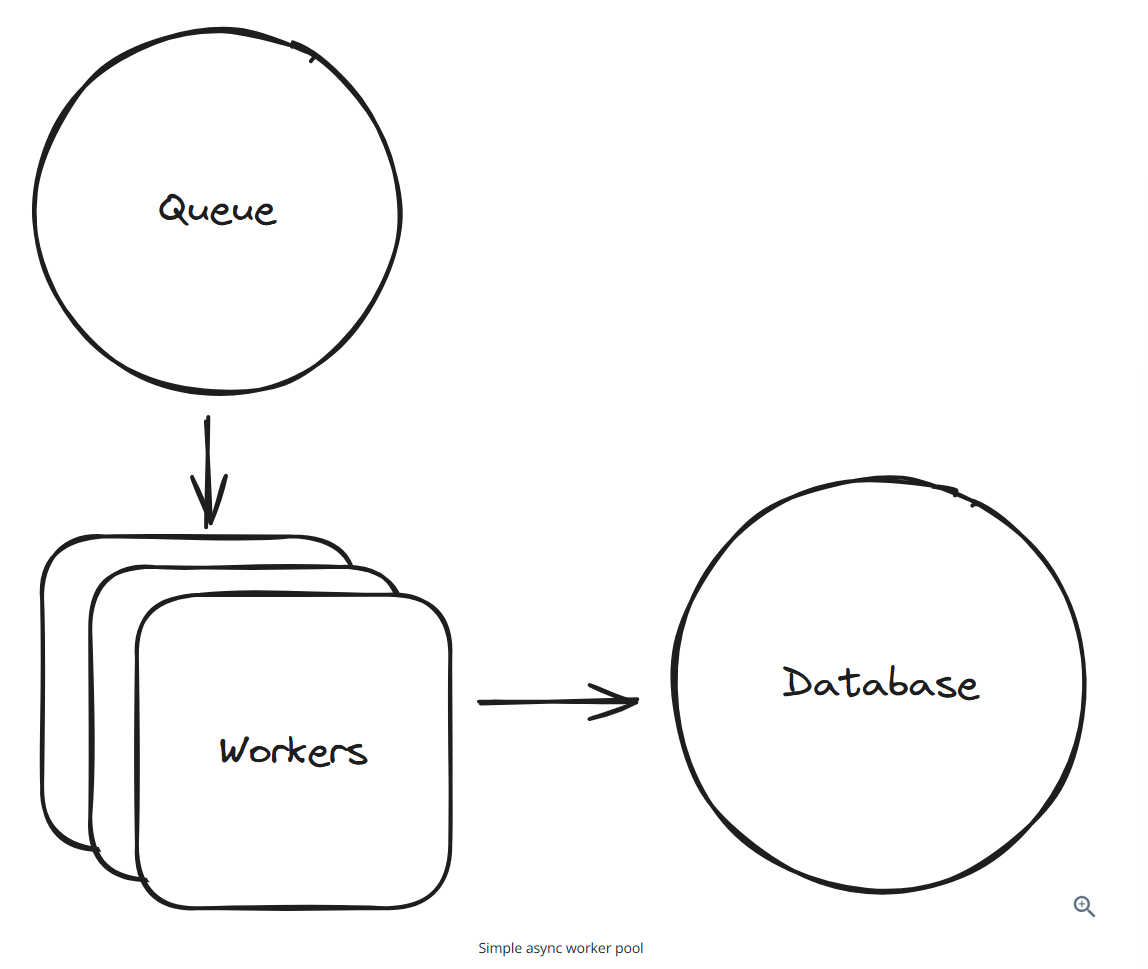
Async job worker pool
If a system needs to handle a lot of processing and can tolerate some delay, you might consider an async job worker pool.
Two stage architecture
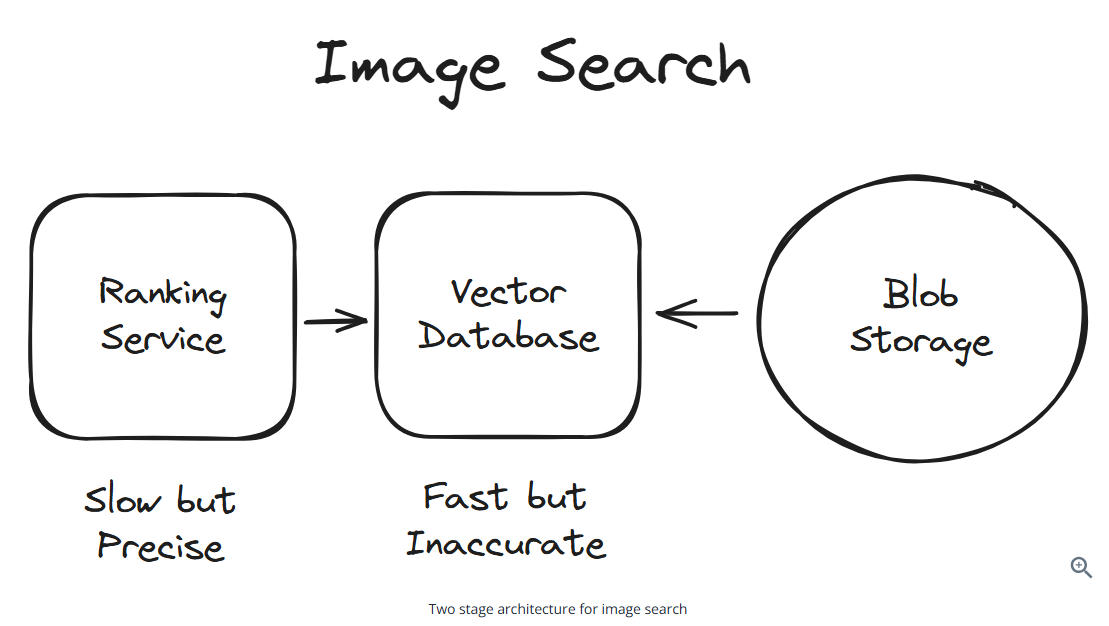
In the first stage, we can use a fast algorithm. In the second stage, we can refine the results.
Event-Driven Architecture
EDA is a design pattern centered around events. EDA helps in building systems that are highly responsive, scalable, and loosely coupled.
The core components of an EDA are event producers, event routers (or brokers), and event consumers.
Durable Job Processing
Checkpoint job progress to the log.
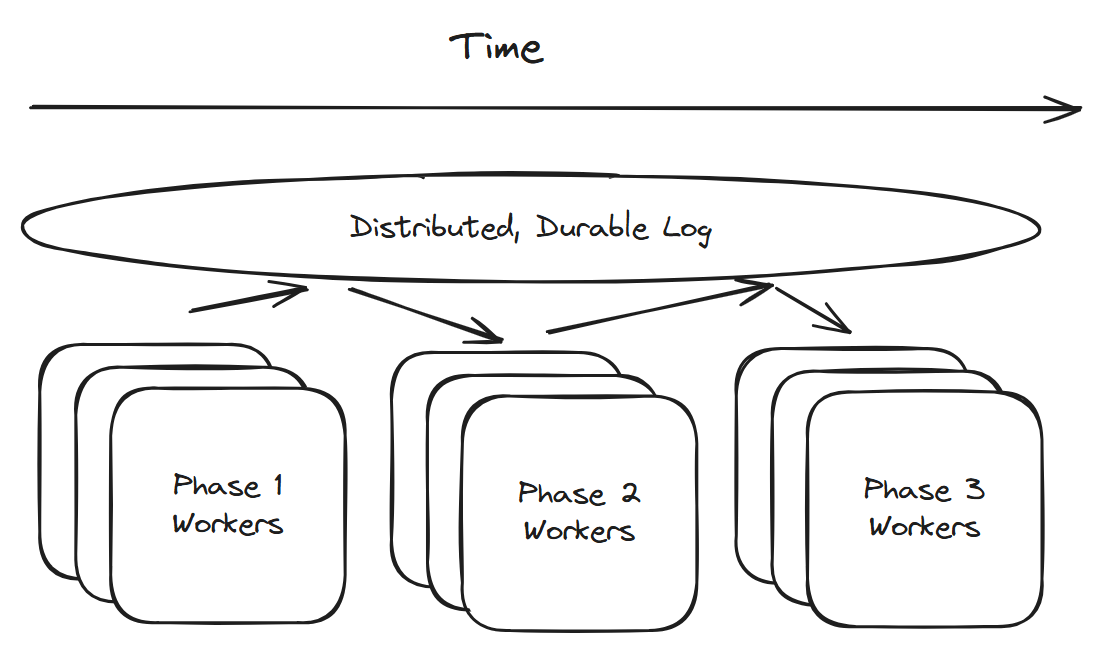
Proximity-Based Services
Some systems may need geospatial indexes.
Geospatial indexes are only necessary when you need to index hundreds thousands or millions items. If you need to search through a map of 1k items, you’re better off scanning all of the items than the overhead of purpose-built index or service.
Core Concepts (In Depth)
Networking Essentials
Networking tends to be a stronger focus in infrastructure and distributed systems interviews.
OSI model
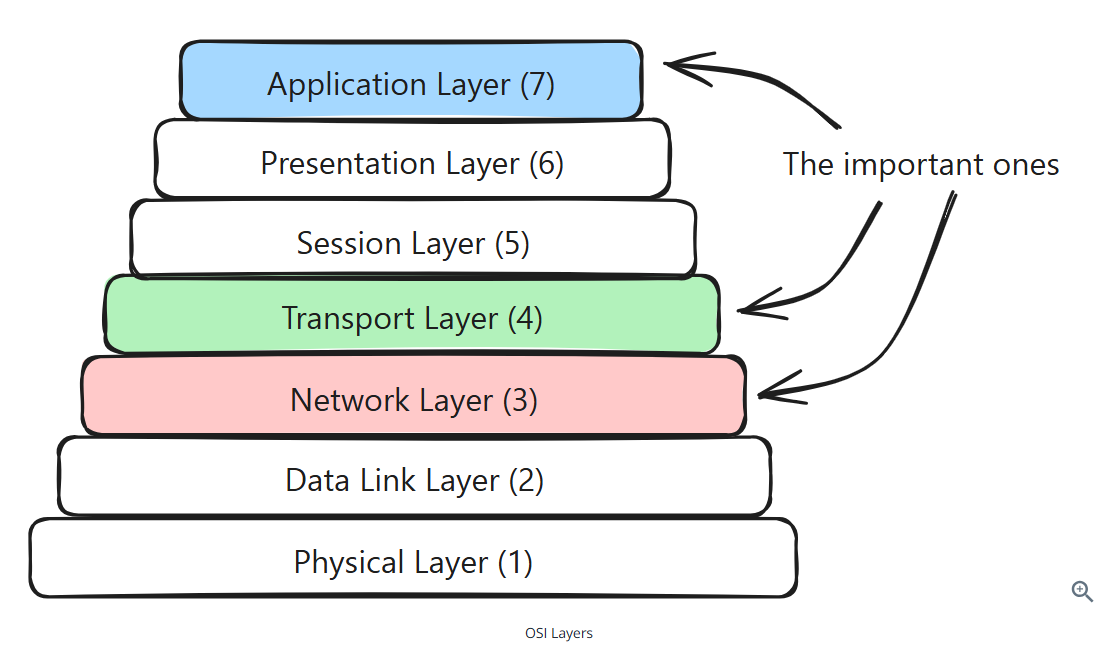
Network Layer (Layer 3)
IP, handles routing and addressing
Transport Layer (Layer 4)
TCP, QUIC, UDP, provides end-to-end communication services
reliability, ordering, and flow control (think about TCP protocol)
Application Layer (Layer 7)
DNS, HTTP, WebSockets, WebRTC, protocols built on top of TCP/UDP
A Web request
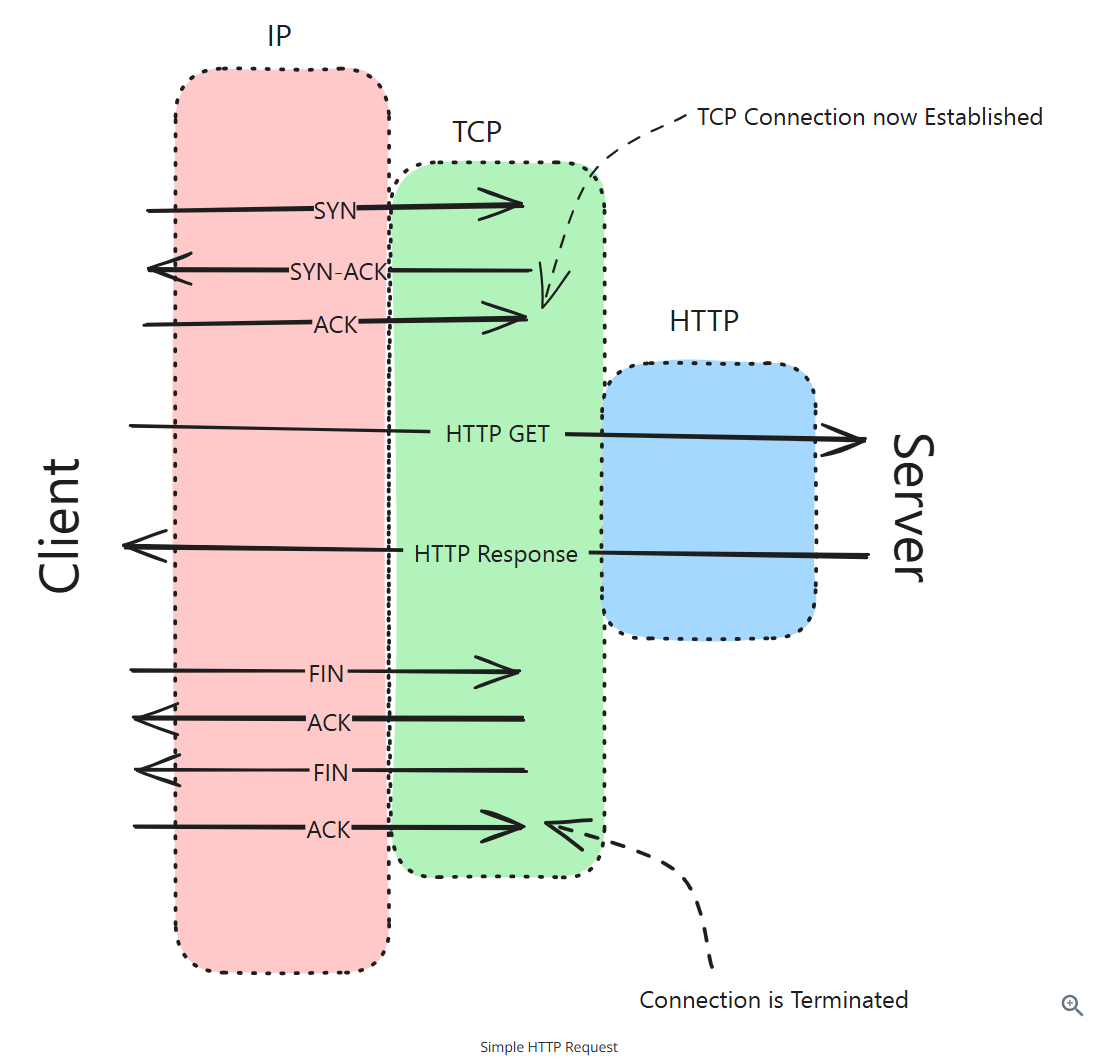
Steps:
- DNS Resolution: The client starts by resolving the domain name of the website to an IP address using DNS
- TCP Handshake: The client initiates a TCP connection with the server using a three-way handshake
- SYN: The client sends a SYN packet to the server to request a connection
- SYN-ACK: The server responds with a SYN-ACK packet to acknoledge the requst
- ACK: The client sends an ACK (acknowledge) packet to establish the connection
- HTTP Request: Once the TCP conneection is established, the client sends an HTTP Get request to the server to request the web page
- Server Proceessing: The server processes the request, retrieves the requested web page, and prepares an HTTP response
- HTTP Response: The server sends the HTTP response back to the client, which includes the requested web page content
- TCP Teardown: After the data transfer is complete, the client and server close the TCP connection using a four-way handshake
- FIN: The client sends a FIN packet to the server to terminate the connection
- ACK: The server acknoledges the FIN packet with an ACK
- FIN: The server sends a FIN packet to the client to terminate its sided of the connection
- ACK: The client acknoledges the server’s FIN packet with an ACK
Network Layer Protocols
Dominated by the IP protocol, responsible for routing and addressing
Transport Layer Protocols
TCP, UDP, QUIC
UDP: Fast but unreliable
- Connectionless: No handshake or connection setup
- No guarantee of delivery: Packets may be lost without notification
- No ordering: Packets may arrive in a different order than sent
- Lower latency: Less overhead means faster transmission
UDP is perfect for applications where speed is more important than reliability, such as live video streaming, online gaming, VoIP, and DNS lookups
TCP: Reliable but with overhead
- Connection-oriented: Establishes a dedicated connection before data transfer
- Reliable delivery: Guarantees that data arrives in order and without errors
- Flow control: Prevents overwhelming receivers with too much data
- Congestion control: Adapts to network congestion to prevent collapse
TCP is ideal for applications where data integrity is critical.

Application Layer Protocols
HTTP: stateless protocol

Common request methods
- GET: Request data from the server. Idempotent
- POST: Send data to the server
- PUT: Updates data on the server
- PATCH: Updates a resource partially
- DELETE: Deletes data from the server. Idempotent
Common status codes
- Success (2xx)
- 200 OK: The request was successful
- 201 Created: The request was successful and a new resource was created
- Moved (3xx)
- 302 Found: The requested resource has been moved temporarily
- 301 Move Permanently: The requested resource has been moved permanently
- Client Error (4xx)
- 404 Not Found: The requested resource was not found
- 401 Unauthorized: The reques requires authentication
- 403 Forbidden: The server understood the request but refuses to authorize it
- 429: Too Many Requests: The client has sent too many requests in a given amount of time
- Server Error (5xx)
- 500 Server Error: The server encountered an error
- 502 Bad Gateway: The server received an invalid response from the upstream server
HTTPS adds a security layer (TLS/SSL) to encrypt communications, protecting against attacks
REST: Simple and flexible
A simple RESTful API looks like
1 | GET /users/:id -> User |
Use PUT to update a pre-existing resource
1 | PUT /users/:id -> User |
Use POST to create new resources
1 | POST /users -> User |
REST is not the most performant solution for high throughput services, and JSON is a pretty inefficient format for serializing and deserializing data.
REST is a good baseline for building scalable systems. Consider GraphQL, gRPC, SSE, or WebSockets for better performance.
GraphQL: Flexible data fetching
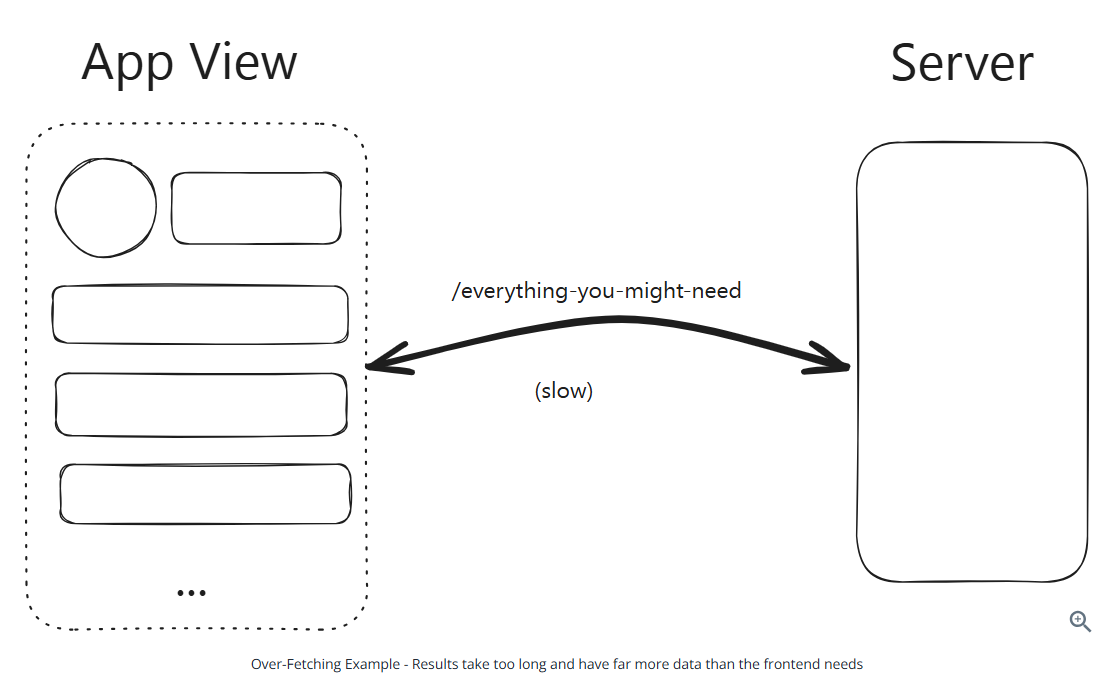
GraphQL allows to query the backend for exactly the data needed.
gRPC: Efficient service communication
gRPC uses HTTP/2 and Protocol Buffers
gRPC is a binary protocol that’s faster and more efficient than JSON over HTTP
gRPC is a good fit for internal service-to-service communication when performance is critical or when latencies are dominated by the network rather than the work the server is doing
gRPC is not a good fit for public-facing APIs, because the binary protocol and the tooling for working with it is less mature than simple JSON over HTTP
Having internal APIs using gRPC and external APIs using REST is a great way to get the benefits of a binary protocol without the complexity of a public-facing API
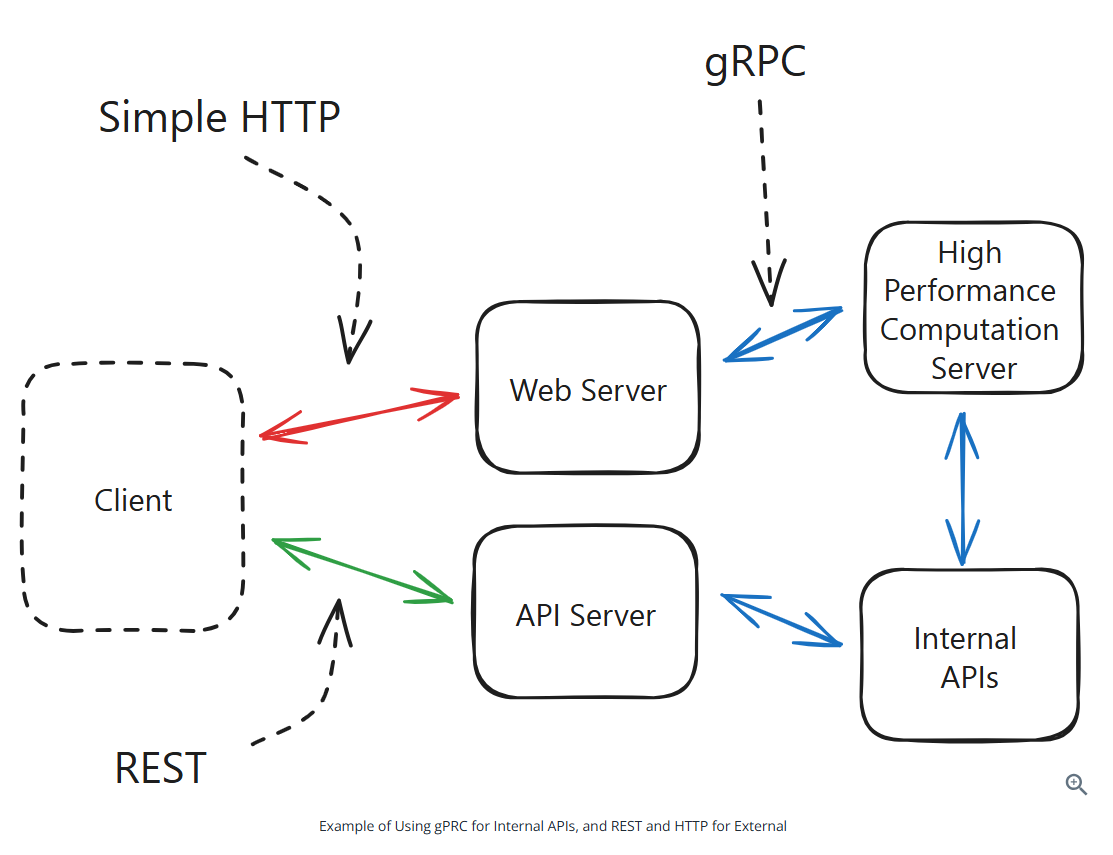
Server-Sent Events (SSE): Real-Time push communication
SSE is a spec defined on top of HTTP that alows a server to push many messages to the client over a single HTTP connection
For most HTTP APIs we have to use a single cohesive JSON blob as a response from the server:
1 | { |
which is not good for push notifications because the client has to wait for the whole response to come in before we can procecss it
SSE allows the server to push many messagess as chunks in a single response
1 | data: {"id": 1, "timestamp": "2025-01-01T00:00:00Z", "description": "Event 1"} |
The client can process each message as it comes in. It’s still one big HTTP response (same TCP connection)
SSE is stateful
SSE is useful in situations where you want clients to get notifications or events as soon as they happen
WebSockets: Real-Time bidirectional communication
WebSockets enables servers to push data to clients without being prompted by a new request
WebSockets are intiated via an HTTP upgrade protocol, which allows an existing TCP connection to change L7 protocols
How it works:
- Clients initiates WebSocket handshake over HTTP (with a backing TCP connection)
- Connection upgrades to WebSocke prtocol, WebSocket takes over the TCP connection
- Both client and server can send binary messages to each other over the connection
- The connection stays open until explicitly closed

WebSockets come up when you need high-frequenc, persistent, bi-directional communication between client and server. For examples, real-time applications, games.
WebSockets are powerful, but the infra required to support them can be expensive an the overhead of stateful connections wll require significant accommodations in the design.
WebRTC: Peer-to-Peer communication
WebRTC enables direct peer-to-peer communication between browsers without requiring an intermediary server for the data exchange.
WebRTC is useful for video/audio calling and conferencing applications
WebRTC uses UDP
Most users are behind a NAT (network address translation) device which keeps them from being connected to directly
WebRTC has a few work around:
- STUN: Session Traversal Utilities for NAT
- TURN: Traversal Using Relays around NAT
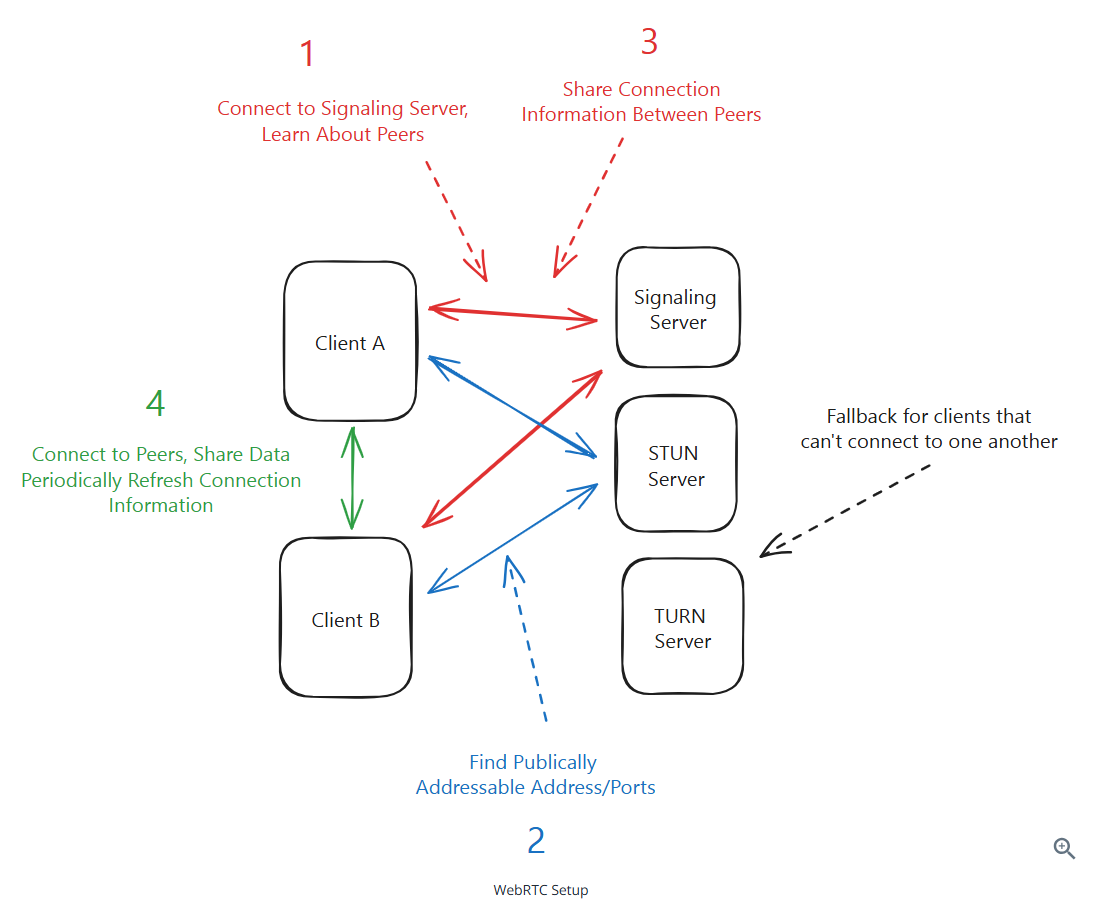
4 steps to a WebRTC connection:
- Clients connect to a central signaling server to learn about their peers
- Clients reach out to a STUN server to get their public P address and port
- Clients share this information with each other via the signaling server
- Clients establish a direct peer-to-peer connection and start sending data
WebRPC is hard to get right. The recommendation is using WebRTC for video/audio calling and conferencing
Load Balancing
Scaling
Client-Side load balancing: The client decides which server to talk to. Fast and efficient. The client can choose the fastest server without any additional latency.
Examples:
- Redis Cluster
- DNS
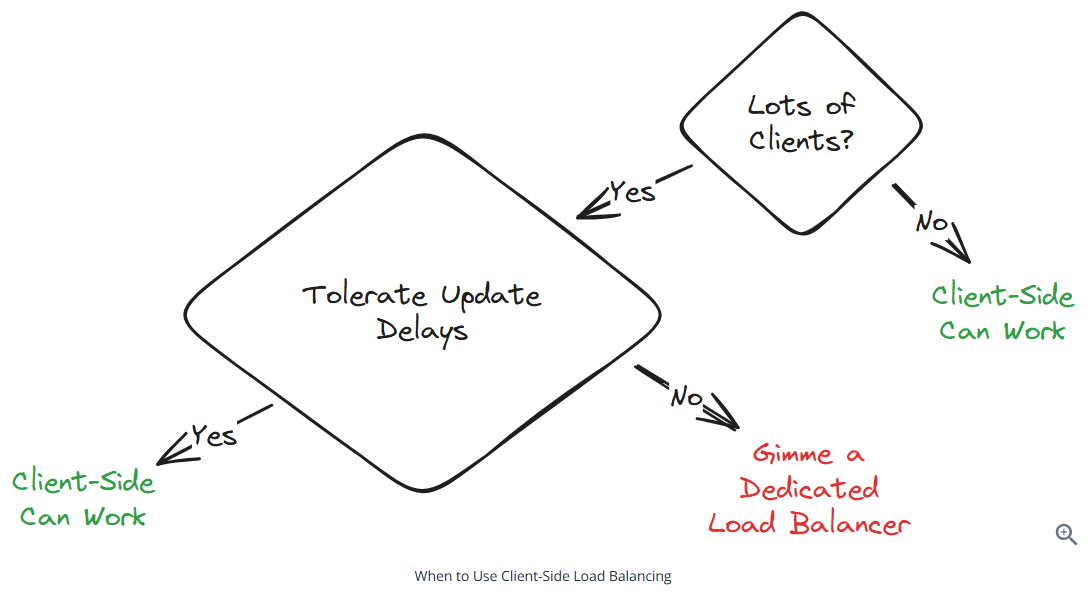
Client-side load balancing works well for internal microservices
Dedicated load balancers
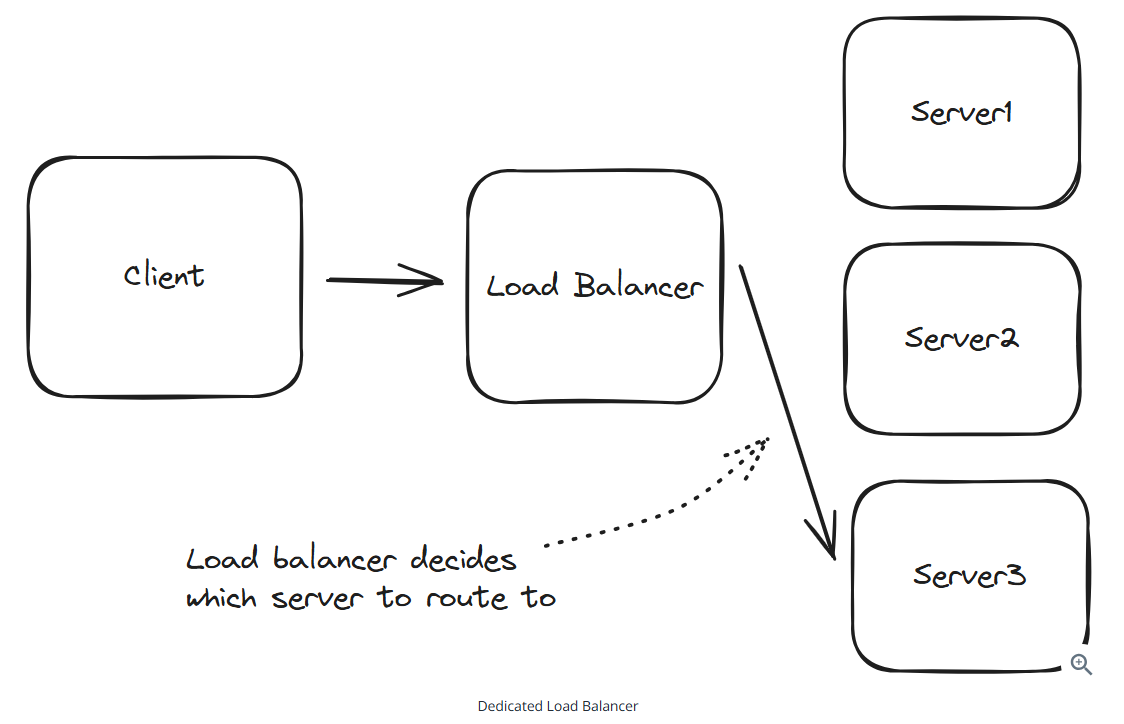
Layer 4 load balancers: operate at the transport layer (TCP/UDP). They make routing decisions based on network information like IP addresses and ports, without looking at the actual content of the packets.
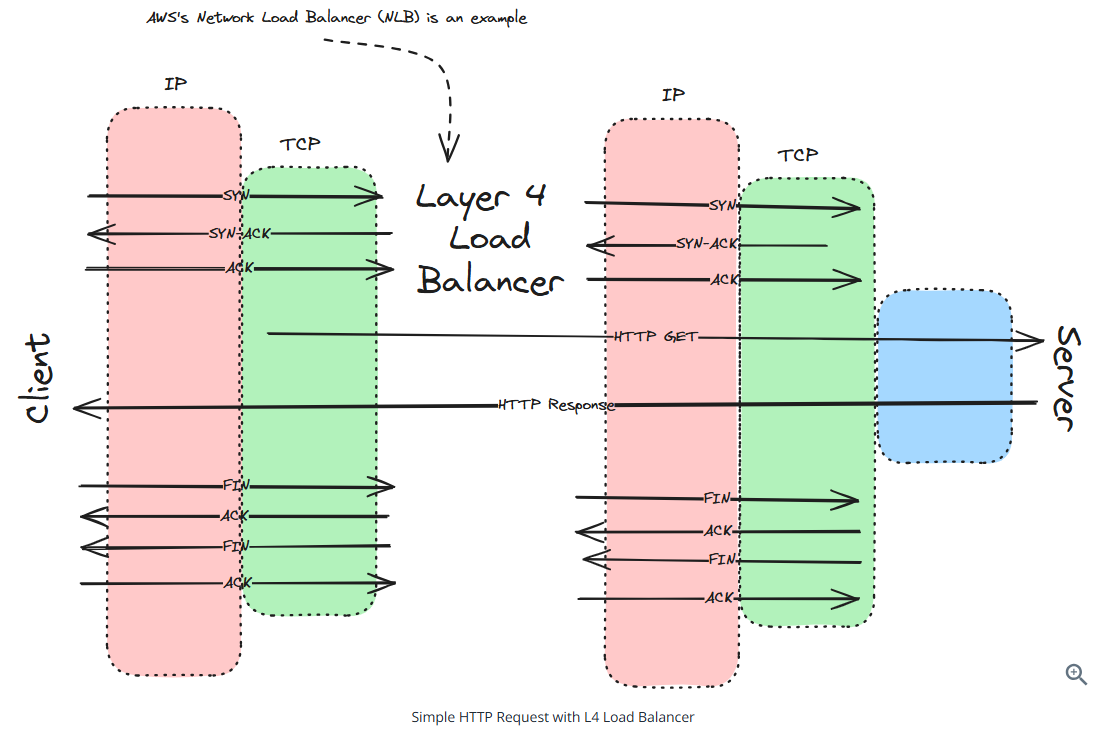
Layer 4 load balancer characteristics
- Maintain persistent TCP connections between client and server
- Are fast and efficient due to minimal packet inspection
- Cannot make routing decisions based on application data
- Are typically used when raw performance is the piority
WebSockets: L4 load balancer
Everything else: L7 load balancer
Layer 7 load balancers: can examine the actual content of each request and make more intelligent routing decisions
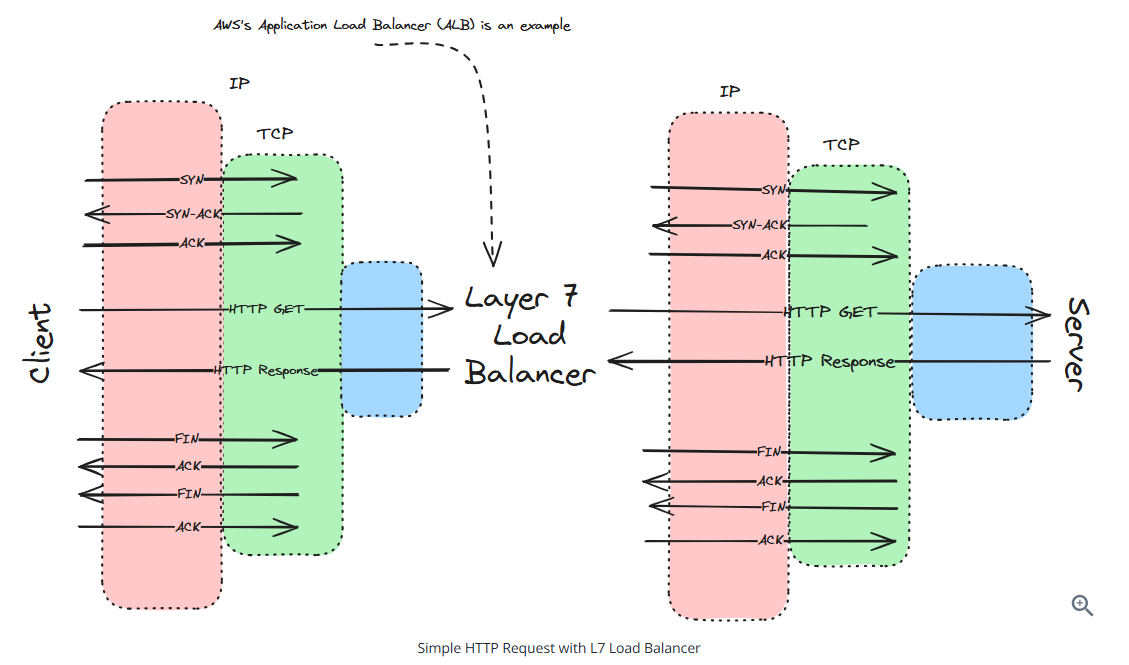
Layer 7 load balancer characteristics
- Terminate incoming connections and create new ones to backend servers
- Can route based on request content
- More CPU-intensive due to packet inspection
- Provide more flexibilty and features
- Better suited for HTTP-based traffic
Load balancers are responsble for monitoring the health of backend servers
Load balancers use health checks to determine if a server is healthy
Load balancing algorithms:
- Round Robin: Requests are distributed sequentially across servers
- Random: Requests are distributed randomly across servers
- Least Connectons: Requests go to the server with the fewest active connections
- Least Response Time: Requests go to the server with the fastest response time
- IP Hash: Client IP determines which server receives the request (useful for session persistence)
Usually Round Robin or Random is appropriate, for stateless applications.
For services that require a persistent connection (SSE or WebSocket), Least Connections is a good choice.
Real-World implementations:
- Hardware Load Balancers: Physical devices like F5 Networks BIG-IP
- Software Load Balancers: HAProxy, NGINX, Envoy
- Cloud Load Balancers: AWS ELB/ALB/NLB, Google Cloud Load Balancing, Azure Load Balancer
If a request takes a certain amount of time, we can set a timeout and if the request takes too long we can give up and try again.
Retrying requests is a great strategy for dealing with transient failures. Retrying requires idempotent APIs.
Backoff: instead of retrying immediately, we wait a short amount of time before retrying. If the request still fails, we wait a little longer. This gives the system time to recover and reduces the load on the system.
In interview, mention “retry with exponential backoff”.
Idempotent APIs: APIs that can be called multiple times and they produce the same result every time.
Idempotency key: a unique idedntifier for a request that we can use to make sure the same request is idempotent.
Circuit breakers: prevent cascading failures across distributed systems and give failing services time to recover
- The circuit breaker monitors for failures when calling external services
- When failures exceeda threshold, the circuit trips to an open state
- While open, requests immediately fail without attempting the actual call
- After a timeout period, the circuit transitions to a half-open state
- A test request determines whether to close the circuit or keep it open
Advantages of circuit breakers:
- Fail Fast: Quickly reject requests to failing services instead of waiting for timeouts
- Reduce Load: Prevent overwhelming already struggling services with more requests
- Self-Healing: Automatically test recovery without full traffic load
- Improved User Experience: Provide fast fallbacks instead of hanging UI
- System Stability: Prevent failures in one service from affecting the entire system
Examples to apply circuit breakers:
- External API calls to third-party services
- Database connections and queries
- Service-to-service communication in microservices
- Resource-intensive operations that might time out
- Any network call that could fail or become slow
CAP Theorem
CAP theorem states that in a distributed system, you can only have two out of three of the following properties:
- Consistency: All nodes see the same data at the same time. When a write is made to one node,all subsequent reads from any node will return that updated value.
- Availability: Every request to a non-failing node receives a response, without the guarantee that it contains the most recent version of the data.
- Partition Tolerance: The system continues t operate despite arbitrary message loss or failure of part of the system.
In any distributed system, partition tolerance is a must. Network failures will happen, and your system needs to handle them.
When to choose consistency:
- Ticket booking systems: do not allow double-booking
- E-commerce inventory: do not allow oversell
- Financial systems: stock trading platforms need to show accurate, up-to-date order books
When to choose availability:
- Social media
- Content platforms (like Netflix)
- Review sites (like Yelp)
If you prioritize consistency, your design might include:
- Distributed transactions: two-phase commit potocols. Users will likely experience higher latency as the system ensures data is consistent across all nodes.
- Single-node solutions: Using a single database to eliminates consistency challenges
- Technology choices
- Traditional RDBMSs (PostgreSQL, MySQL)
- Google Spanner
- DynamoDB (in strong consistency mode)
If you prioritize availability, your design can include:
- Multiple replicas: multiple read replicas improve read performance and availability at the cost of potential staleness.
- Change data capture (CDC): Using CDC to track changes in the primary database and propagate them asynchronously to replicas, caches, and other systems. This allows the primary system to remain available while updates flow through the system eventually.
- Technology choices
- Cassandra
- DynamoDB
- Redis clusters
Real-world examples
Ticketmaster needs different consistency models for different features within the same system:
- Booking a seat at an event: Requires strong consistency to prevent double-booking
- Viewing event details: Can priortize availability
Tinder has mixed requirements too:
- Matching: Needs consistency
- Viewing a user profile: Can priortize availability
Different levels of consistency:
- Strong consistency: All reads reflect the most recent write.
- Causal consistency: Related events appear in the same order to all users. This ensures logical ordering of dependent actions.
- Read-your-own-writes consistency: Users always see their own updates immediately, though other users might see older versions. Commonly used in social media platforms where users expect to see their own profile updates right away.
- Eventual consistency: The system will become consistent over time but may temporarily have inconsistencies. This is the most relaxed form of consistency and is often used in systems like DNS where temporary inconsistencies are acceptable.
Consistent Hashing
Consistent hashing is a technique that solves the problem of data redistribution when adding or removing an instance in a distributed system.
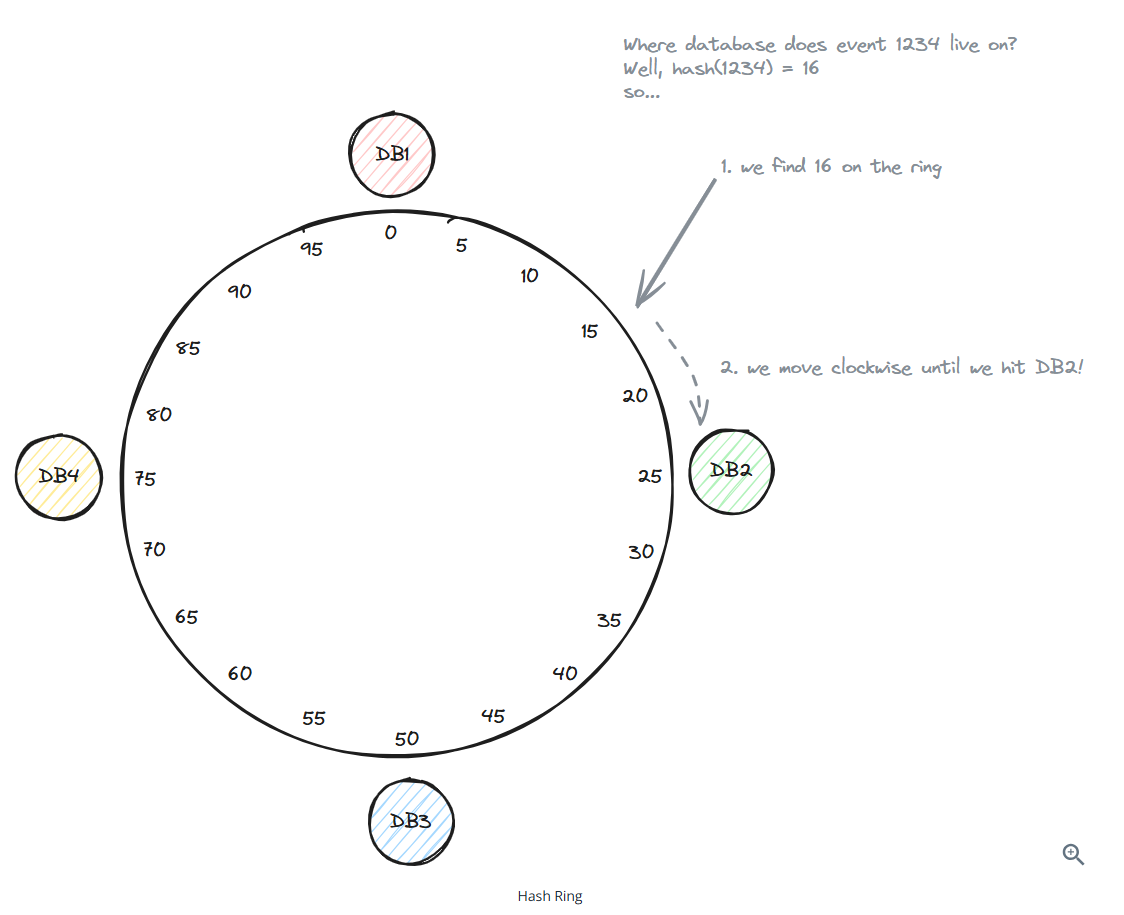
Adding a database (database 5)
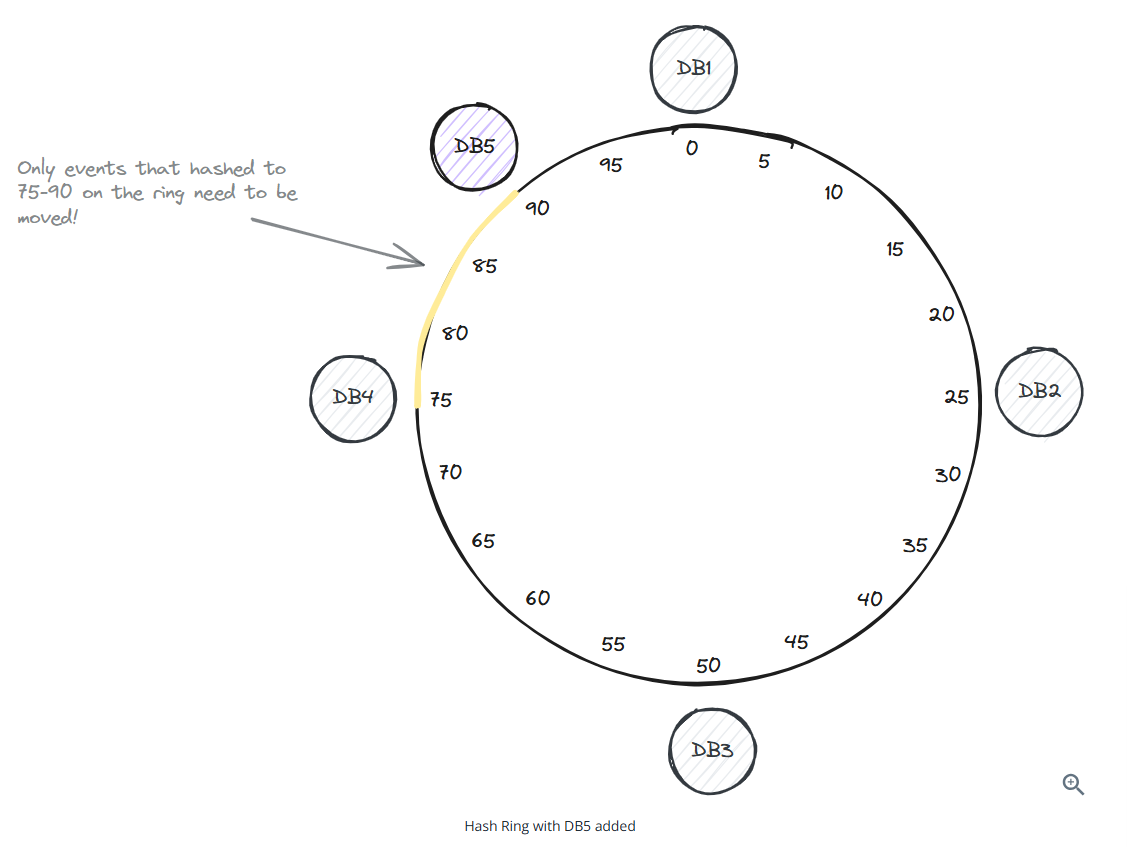
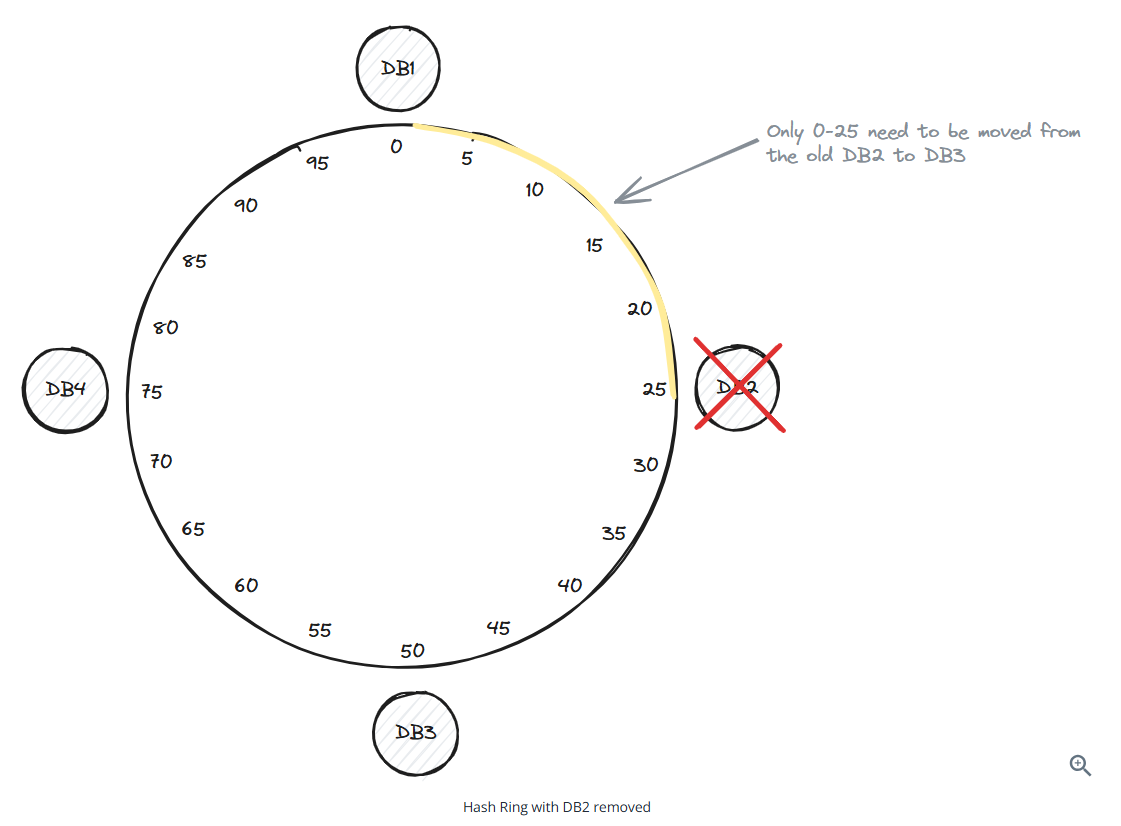
Removing a database (database 2)
To have even distribution, use virtual nodes
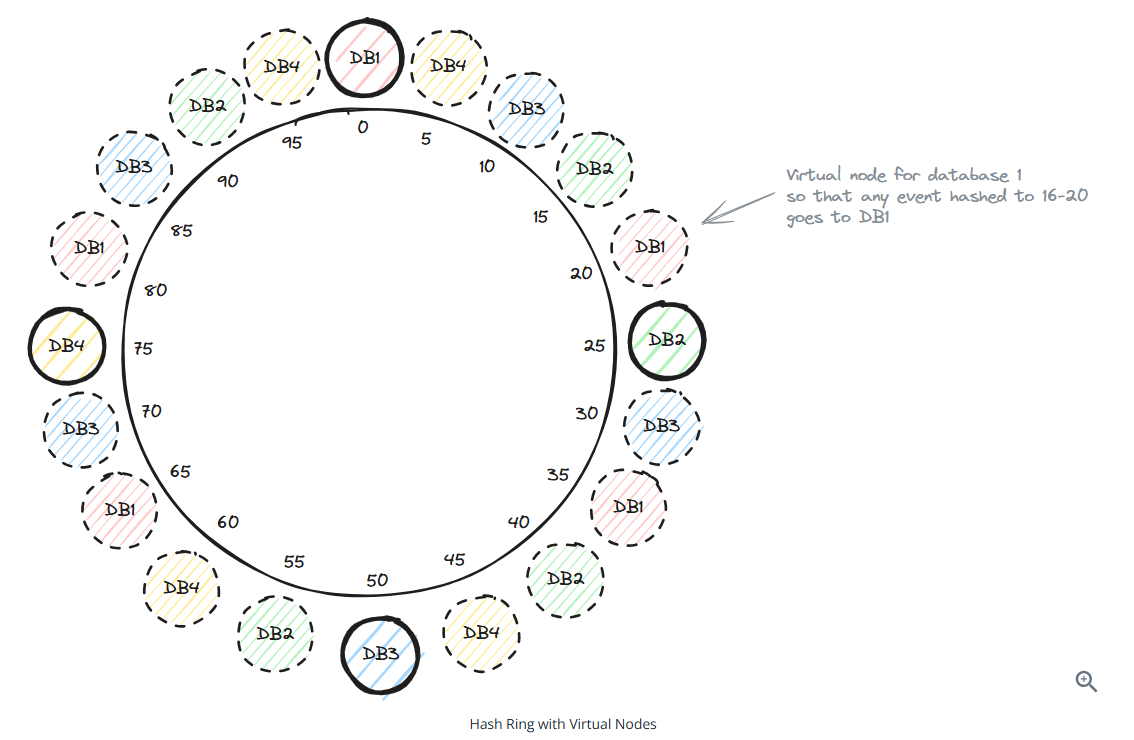
The more virtual nodes you use per database, the more evenly distributed the load becomes.
Consistent hashing in the real world:
- Redis Cluster: Uses consistent hashing to distribute keys across nodes
- Apache Cassandra: Uses consistent hashing to distribute data across the ring
- Amazon’s DynamoDB: Uses consistent hashingg under the hood
- Content Delivery Networks (CDNs): Use consistent hashing to determne which edge server should cache specific content
Consistent hashing is a crucial topci in nfrastructure-focused interviews. Common scenarios:
- Design a distributed database
- Design a distributed cache
- Design a distributed message broker
Key Technologies (In Depth)
Redis
Redis is written in C. It’s in-memory and single threaded.
Some of the most fundamental data structures supported by Redis:
- Strings
- Hashes (Objects)
- Lists
- Sets
- Sorted Sets (Priority Queues)
- Bloom Filters
- Geospatial Indexes
- Time Series
Redis infrastructure configurations:
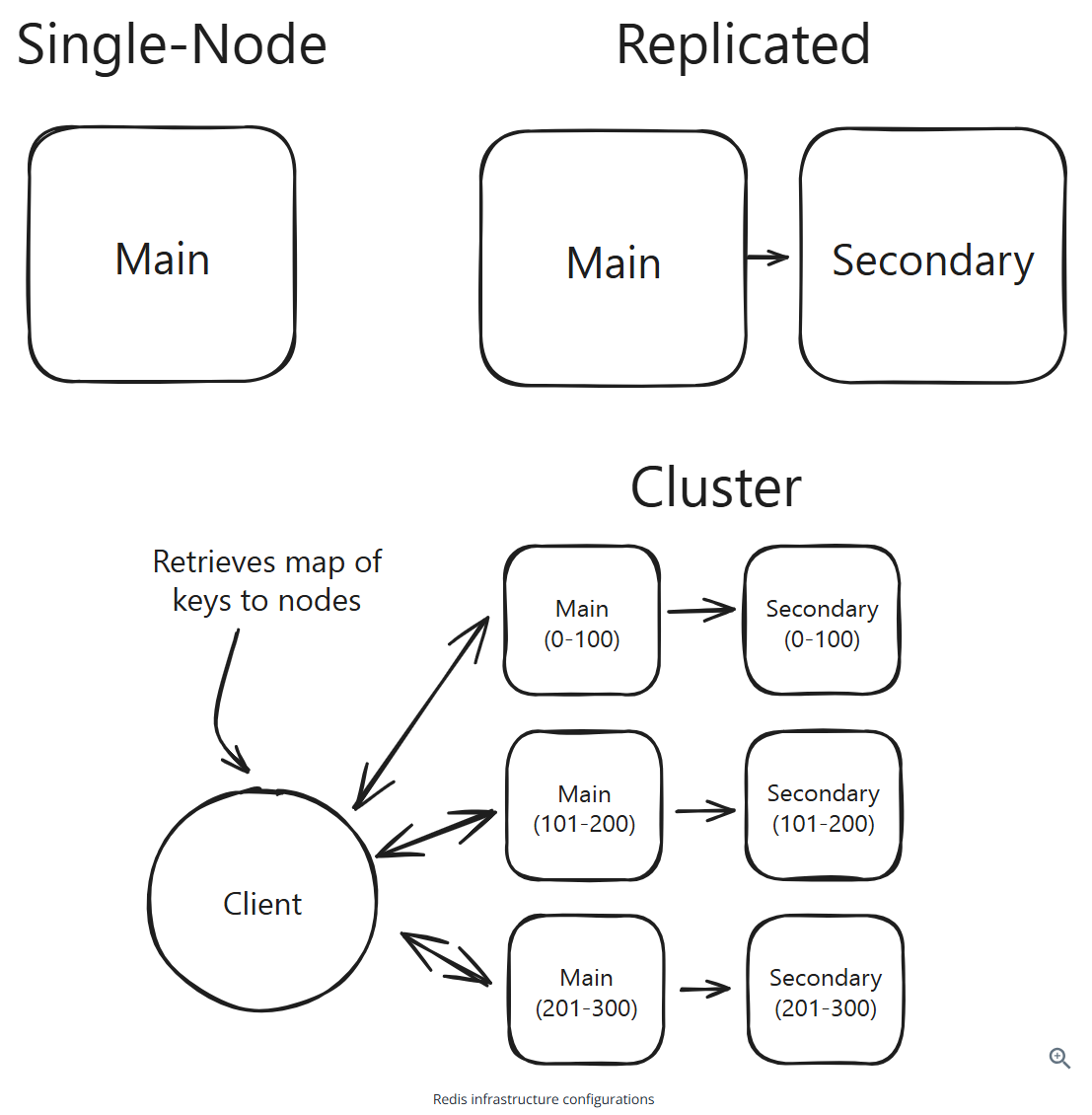
Redis expects all the data for a given request to be on a single node.
Redis can handle O(100k) writes per second and read latency is in microsecond range.
Redis as a Cache
This is the most common deployment scenario of Redis.
Redis as a Distributed Lock
A very simple distributed lock with a timeout is using the INCR command with a TTL.
More sophisticated locks in Redis can use the Redlock algorithm.
Redis for Leaderboards
We can use sorted set to create leaderboards.
Redis for Rate Limiting
Example: a fixed-window rate limiter
Redis for Proximity Search
Redis natively support geospatial indexes with commands like GEOADD and GEOSEARCH.
Redis for Event Sourcing
Redis for Pub/Sub
Chat room example using Pub/Sub pattern with Redis:
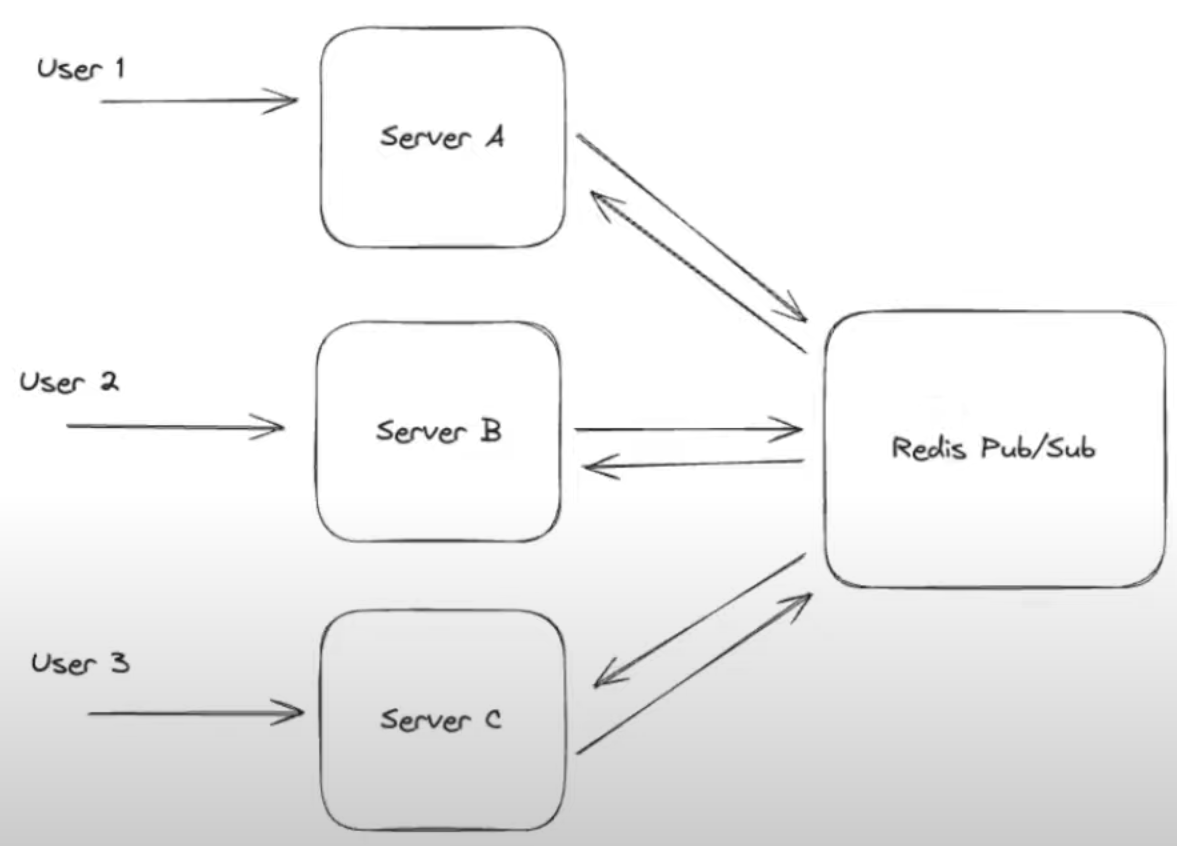
Redis supports at most once delivery
Hot Key Issues
When the load is not evenly distributed across the keys in Redis cluster.
Potential solutions:
- Add an in-memory/in-process cache in clients
- Store the same data in multiple keys and randomize the requests so they are spread across the cluster
- Add read replicas to scale
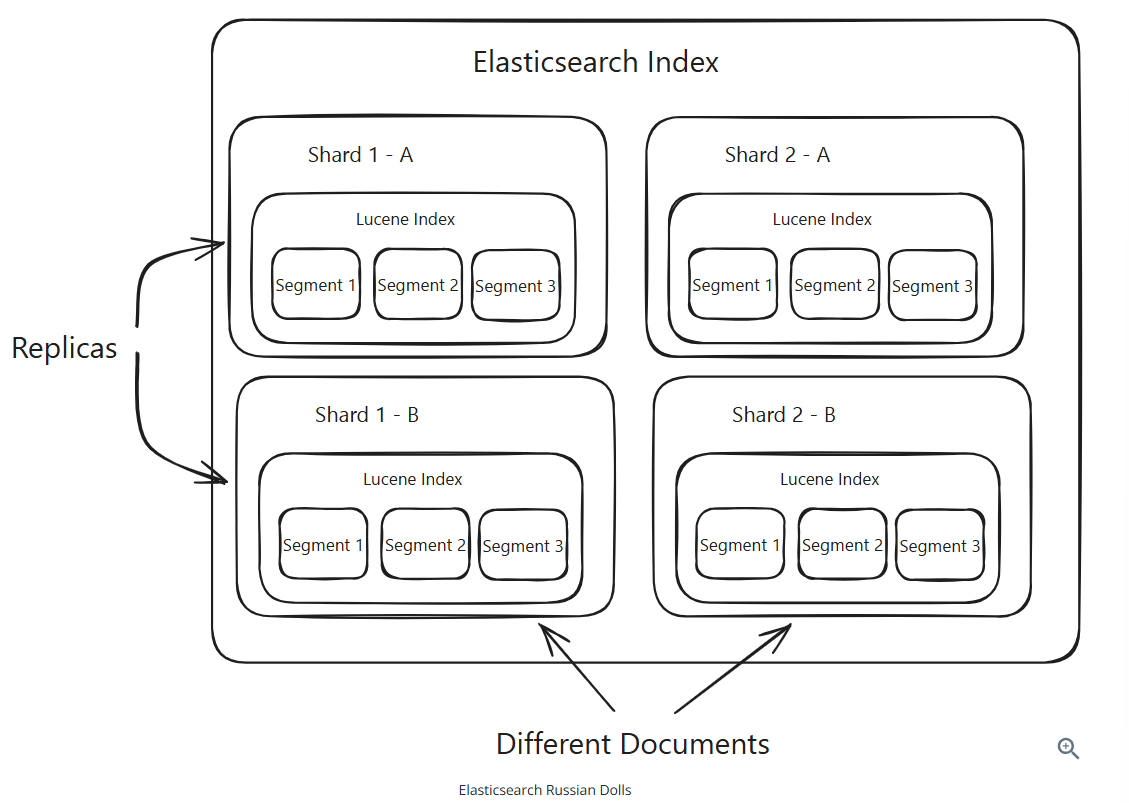
ElasticSearch
Basic concepts
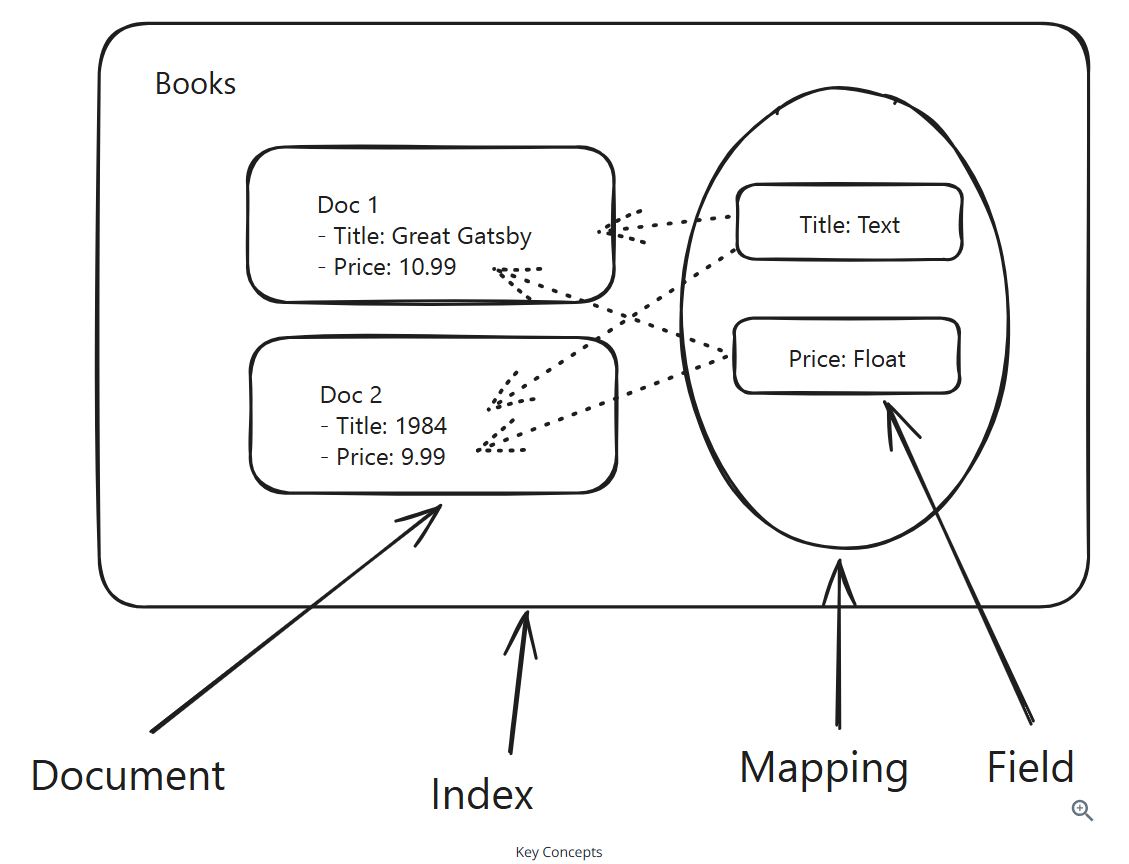
Documents: Individual units of data that you’re searching over
1 | { |
Indices: A collection of documents. Each document is associated with a unique ID and a set of fields, which are key-value pairs that contain the data you’re searching over.
Mappings and Fields: A mapping is the schema of the index. It defines the fields that the index will have, the data type of each field, and any other properties like how the field is processed and indexed. The mapping determines which fields are searchable and what type of data they contain.
1 | { |
Including too many fields will increase the memory overhead of each index and degrade performance.
Create an Index
A simple PUT request will create an index with a dynamic mapping, 1 shard, and 1 replica
1 | // PUT /books |
Set a Mapping
1 | // PUT /books/_mapping |
Add Documents
Request:
1 | // POST /books/_doc |
Response:
1 | { |
Update Documents
1 | // PUT /books/_doc/kLEHMYkBq7V9x4qGJOnh |
We can update a specific version (an example of optimistic concurrency control):
1 | // PUT /books/_doc/kLEHMYkBq7V9x4qGJOnh?version=1 |
Search
Search for books with “Great” in the title:
1 | // GET /books/_search |
Search for books with “Great” in the title that are priced less than 15 dollars:
1 | // GET /books/_search |
Sort
Sorting allows you to order search results based on specific fields
1 | // GET /books/_search |
Pagination and Cursors
Pagination allows you to retrieve a subset of search results, typically used to display results across multiple pages.
From/Size pagination:
from: The starting index of the resultssize: The number of results to return
Example query with pagination:
1 | // GET /my_index/_search |
Cursors provides a stateful way to paginate through search results, solving the problem of the documents shifting.
Cluster Architecture
Node types:
- Master Node: responsble for coordinating the cluster. It’s the only node that can perform cluster-level operations like adding or removing nodes, and creating and deleting indices.
- Data Node: responsible for storing the data. It’s where your data is actually stored.
- Coordinating Node: responsible for coordinating the search requests across the cluster. It’s the node that receives the search request from the client and sends it to the appropriate nodes. This is the frontend for the cluster.
- Ingest Node: responsible for data ingestion. It’s where data is transformed and prepared for indexing.
- Machine Learning Node: responsible for machine learning tasks.
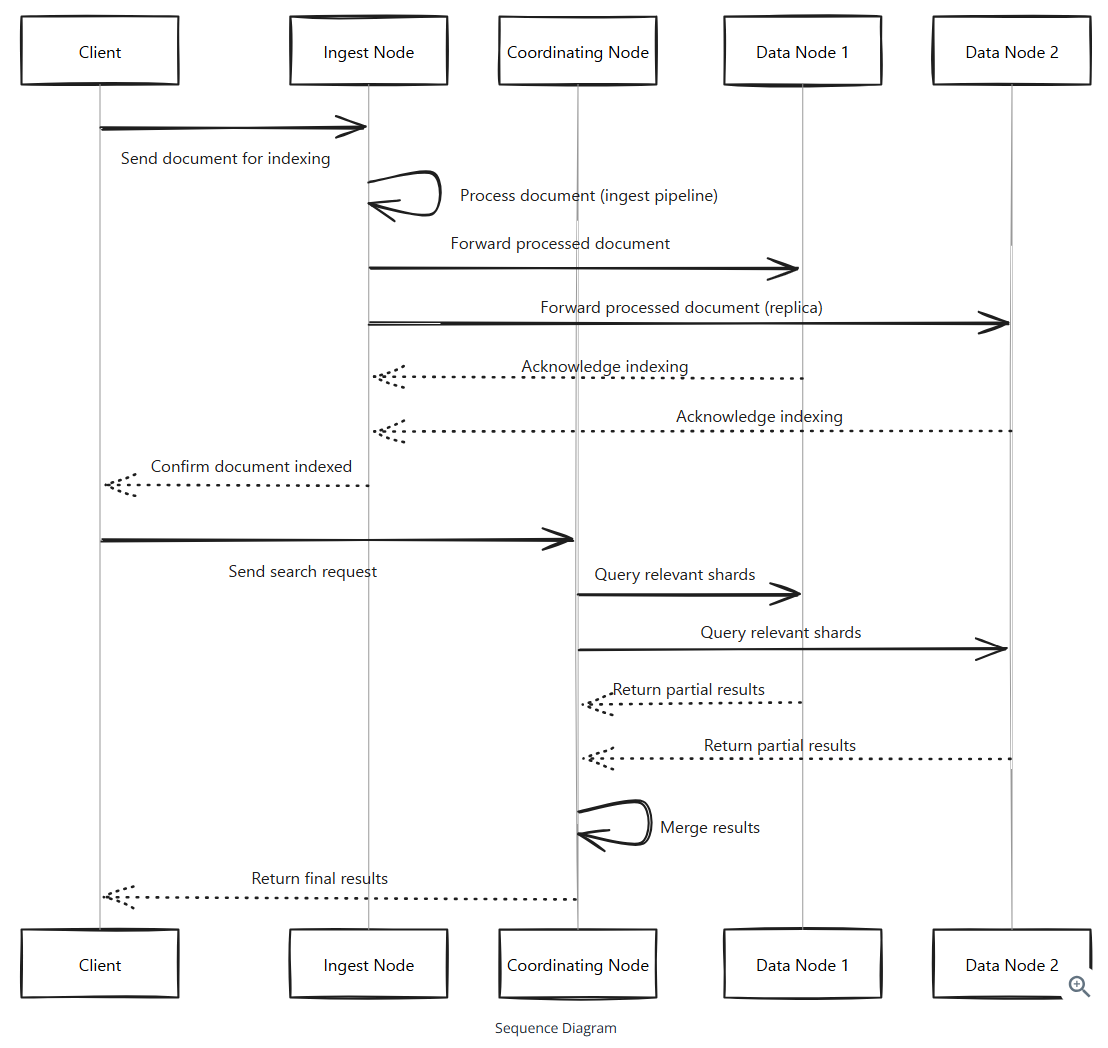
Data Nodes
Kafka
Apache Kafka is an open-source distributed event streaming platform that can be used either as a message queue or as a stream processing system.
A stream processing example:
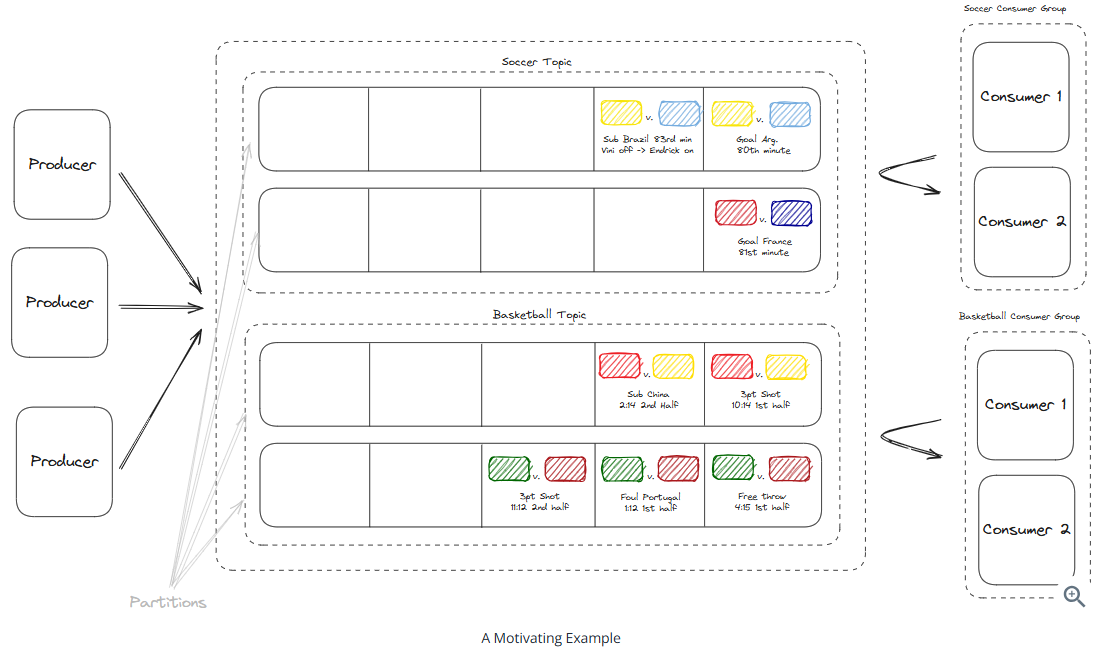
Messages sent and received through Kafka require a user specified distribution strategy.
Basic terminology:
- Broker: A Kafka cluster is made up of multiple brokers. Each broker is an individual server (can be physical or virtual) and is responsible for storing data and serving clients.
- Partition: Each broker has a number of partitions. Each partition is an ordered, immutable sequence of messages that is continually appended to. (like an AOF)
- Topic: A logical grouping of partitions. Topics are always multi-producer.
- Producer: The ones who write data to topics
- Consumer: The ones who read data from topics
A message in Kafka’s context consists of one required field, the value, and three optional fields:
- A key: Used for determine which parttion the message is sent to. If not provided, Kafka will randomly assign the message to a partition. You’ll likely want to use keys to ensure messages are processsed in order (from the same partition).
- A timestamp: Used for ordering
- Headers: key-value pairs that can be used to store metadata about the message
Partition selection process (2 phases):
- Partition Determination: Hashes the message key to assgin the message to a specific partition. The same key always go to the same partition, preserving order at the partition level.
- Broker Assignment: Determines whch broker holds that particular partition. The producer uses mapping metadata to send the message to the broker that hosts the target partition.
Each partition in Kafka operates as an append-only log file. Benefits of this design:
- Immutability: Once written, messages in a partition cannot be altered or deleted. Crucial for Kafka’s performance and reliability.
- Efficiency: Minimizes disk seek times, which are a major bottleneck in many storage systems.
- Scalability: Append-only log facilitates horizontal scaling. More partitions can be added and distributed across a cluster of brokers to handle increasing loads. Each partition can be replicated across multiple brokers to improve read performance and enhance fault tolerance.
Each message in a Kafka partition is assigned a unique offset, which is a sequential identifier indicating the message’s position in the partition.

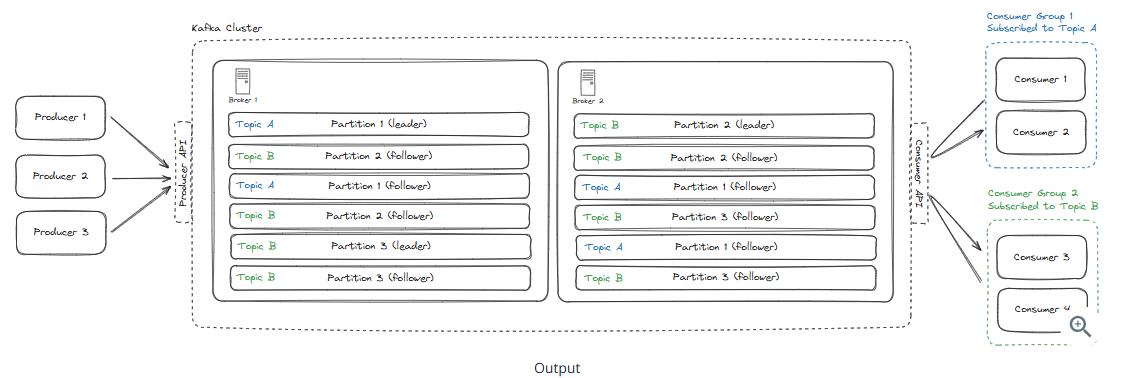
Leader-follower model:
- Leader Replica Assignment: Each partition has a designated leader replica, which resides on a broker. The leader replica is responsible for handling all read and write requests for the partition.
- Follower Replication: Alongside the leader replica, several follower replicas exist for each partition, residing on different brokers. They passively replicate the data from the leader replica, act as backups, ready to take over should the leader replica fail.
- Synchronization and Consistency: Followers continuously sync with the leader replica to ensure they have the latest set of messages appended to the partition log, which is crucial for maintaining consistency across the cluster. If the leader replica fails, one of the follower replicas that has been fully synced will be proomoted to be the new leader, minimizing downtime and data loss.
- Controller’s Role in Replication: The controller within the Kafka cluster manages the replication process. It monitors the health of all brokers and manages the leadership and replication dynamics.
Consumers read messages from Kafka topics using a pull-based model.
Consider using Kafka as a message queue when:
- You have processing that can be done asychronously. YouTube is an example for video uploading, transcoding.
- You need to ensure that messages are processed in order.
- You want to decouple the producer and consumer so that they can scale independently. Usually this means that the producer is producing messages faster than the consumer can consume them and the message queue can serve as a a buffer.
Consider using Kafka as a stream processing middleware when:
- You require continuous and immediate processing of incoming data (real-time flow).
- Messages need to be processed by multiple consumers simultaneously. Used as a Pub/Sub system.
Scalability
- Horizontal scaling with more brokers: Helps distribute the load and offers greater fault tolerance. Each broker can handle a portion of the traffic, increasing the overall capacity of the system.
- Partitioning strategy: Done by choosing a key for messages. Bad paritions can result in hot-key problems. Good keys are ones that are evenly distributed across the partition space.
To scale a topic, we can increase the number of partitions associated with that topic.
Dealing with hot partitions:
- Random paritioning with no key: Randomization. Losing the ability to gurantee order of messagses. If ordering is not important, this is good option.
- Random salting: We can add a random number or timestamp when generating the partition key. This can help in distributing the load more evenly across multiple partitions.
- Use a compound key
- Back pressure: Slow down the producer.
Fault Tolerance and Durability
Kafka ensures data durability through its replication mechanism. Each partition is replicated across multiple brokers.
When a consumer fails, Kafka’s fault tolerance mechanisms help ensure continuity:
- Offset Management: Consumers commit their offset to Kafka after they process a message. When a consumer fails and restarts, it reads its last committed offset and can continue from there.
- Rebalancing: When part of a consumer group fails, Kafka can redistribute the partitions among the remaining consumers so that all partitions are still being processed.
Handling Retries and Errors
The clients to Kafka may fail with a variety of reasons.
If we fail to get a message to Kafka in the first place, Kafka producers support automatic retries.
If we fail to process a message from Kafka, we need our own retry logic. One common pattern is to set up a custom topic that we can move failed messages toand then have a separate consumer that processes these messages. If a message is retried too many times, we can move it to a DLQ.
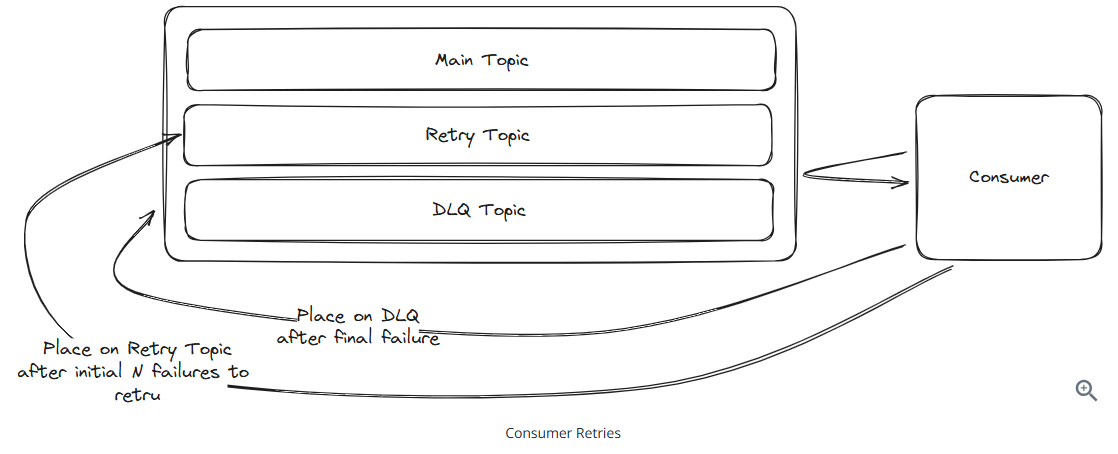
Performance Optimizations
Several strategies to improve performance:
- batching
- compressing the messages on the producer
- choosing a good partition key for scalability
Retention Policies
Kafka topics have a retention policy that determines how long messages are retained in the log. Retention policies incur storage cost and performance.
Lastly
Kafka is always available, sometimes consistent.
API Gateway
An API Gateway serves as a single entry point for all client requests, managing and routing them to appropriate backend services. An API Gateway manages centralized middleware like authentication, routing, and request handling.
Core Responsibilities
The gateway’s primary function is request routing - determining which backend service should handle each incoming request.
Nowadays, API gateways are also used for authentication, rate limiting, caching, SSL termination, and more.
A few responsibilities include:
- Request validation
- API Gateway applies middleware (auth, rate limiting, etc.)
- API Gateway routes the request to the appropriate backend service
- Backend service processes the request and returns a response
- API Gateway transforms the response and returns it to the client
- Optionally cache the response for future requests
Cacheing strategies:
- Full Response Caching: Cache entire responses for frequently accessed endpoints
- Partial Caching: Cache specific parts of responses that change infrequently
- Cache Invalidation: Use TTL or event-based invalidation
Scaling an API Gateway
API Gateways are typically stateless, which is idea for horizontal scaling.
Load balacing:
- Client-to-Gateway Load Balancing: Typically handled by a dedicated load balance in front of the API Gateway.
- Gateway-to-Service Load Balancing: The API Gateway itself can perform load balancing across multiple instances of backend services.
Global Distribution:
- Regional Deployments: Deploy gateway instances in multiple geographic regions
- DNS-based Rouing: Use GeoDNS to route users to the nearest gateway
- Configuration Synchronization: Ensure routing rules and policies are consistent across regions
Popular API Gateways
Managed Services: easiest option but also the most expensive
- AWS API Gateway
- Azure API Managemet
- Google Cloud Endpoints
Open Source Solutions: more control or running on-premises
- Kong
- Tyk
- Express Gateway
When to Propose an API Gateway
Use it when you have a microservices architecture and don’t use it when you have a simple client-server architecture.
The gateway provides a clean separation between the internal service architecture and the external API surface.
For simple monolithic applications or systems with a single client, introducing an API Gateway may be overkill.
Do not spend too much time on the API Gateway during an interview.
Cassandra
Apache Cassandra is a wide-column store with eventually consistent semantics. It is a distributed databases that runs in a cluster and can horizontally scale via commodity hardware.
Data Model
- Keyspace: Data containers
- Table: A table is container for your data, in the form of rows.
- Row: A row is a container for data. It is represented by a primary key and contains columns.
- Column: A column contains data belonging to a row.
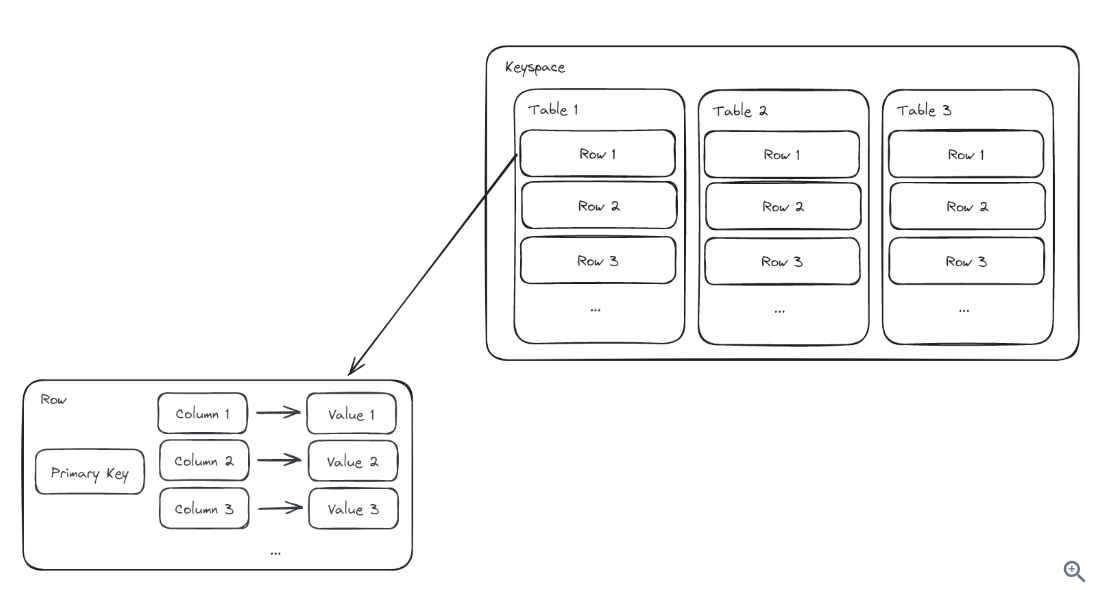
Represented by a JSON blob:
1 | { |
Primary Key: Each row is represented uniquely by a primary key.
- Partition Key: One or more columns that are used to determine what partition the row is in.
- Clustering Key: Zero or more columns that are used to determine the sorted order of rows in a table.
Key Concepts
Partitioning
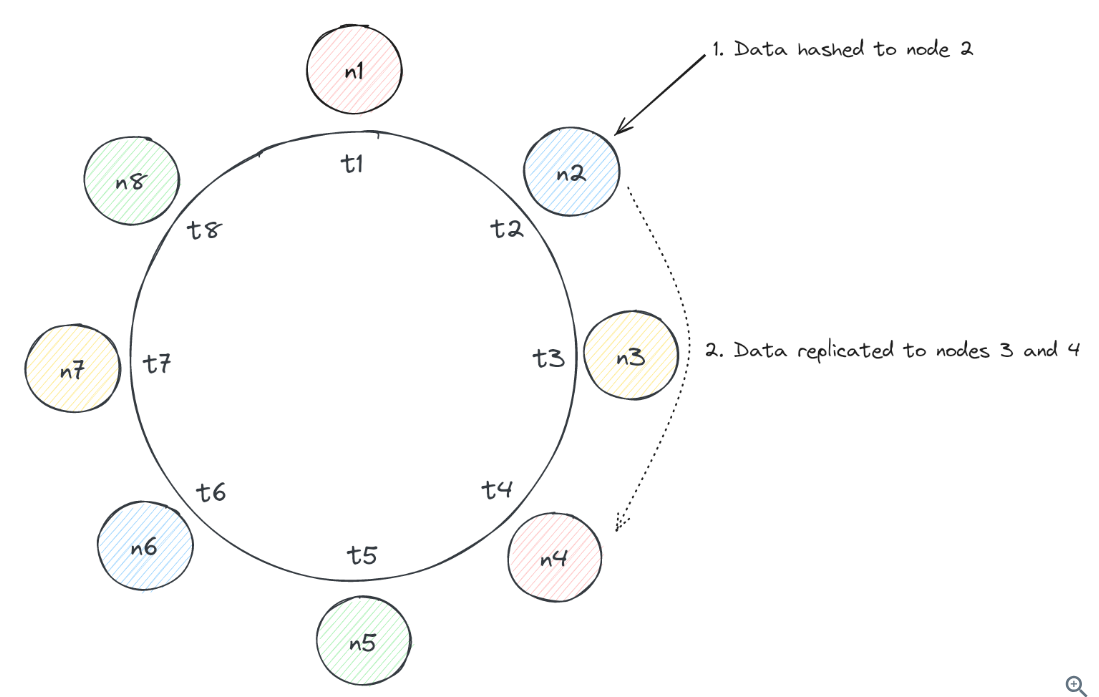
Cassandra achieves horizontal scalability by partitioning data across many nodes in its cluster. Cassandra makes use of consistent hashing.
Replication
An example to replicate data to 3 nodes:
Consistency
Cassandra is subject to the CAP theorem.
Cassandra doesn’t offer transaction support or any notion of ACID gurantees. (Because it’s a NoSQL)
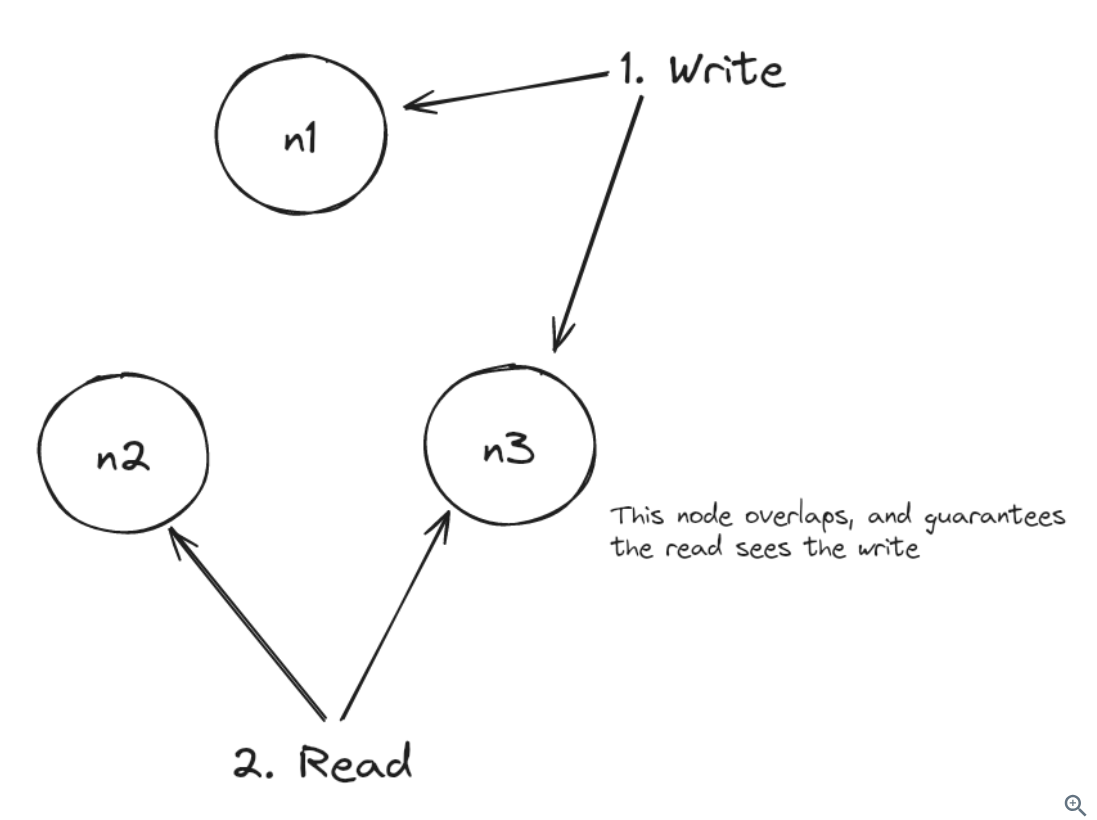
Cassdra provides different levels of consistency as described here. Among which a notable one is QUORUM, which requires a majority (n/2 + 1) of replicas to respond. It guarantees that writes are visible to read because one overlapping node is guaranteed to participate in both a write and a read.
An example of 3 nodes with QUORUM protocol:
Cassandra aims for eventual consistency for all consistency levels.
Query Routing: When a client from the client application comes, a Cassandra node can play as a query coordinator and serves the query by talking to other nodes via a gossip protocol.
Storage Model
Cassandra leverages a data structure called a Log Structured Merge Tree (LSM tree) to improve its write throughput.
Cassandra opts for an approach that favors write speed over read speed. Every create / update / delete is a new entry (with some exceptions, but this is what event sourcing does). Cassandra uses the ordering of these events to determine the state of a row.
3 core concepts for LSM tree index:
- Commit Log: A write-ahead-log to ensure durability of writes for Cassandra nodes
- Memtable: An in-memory, sorted data structure that stores write data. Sorted by primary key of each row.
- SSTable: Sorted String Table: Immutable file on disk containing data that was flushed from a previous Memtable.
Writes look like this:
- A write is issued for a node.
- The write is written to the commit log so it doesn’t get lost if the node goes down while the write is being processed or if the data is only in the Memtable when the node goes down. (Durability guarantee)
- The write is written to the Memtable.
- Eventually, the Memtable is flushed to disk as an immutable SSTable after some threshold size is hit or some period of time elapses.
- When a Memtable is flushed, any commit log messages are removed that correspond to that Memtable, to save space (purge step).
Dataflow diagram:
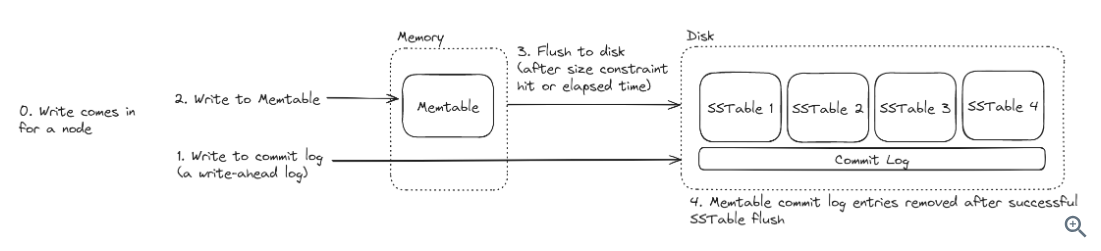
When reading data for a particular key, Cassandra reads the Memtable first, which will have the latest data. If the Memtable does not have the data for the key, Cassandra leverages a bloom filter to determine which SSTables on disk might have the data, and reads the SSTables accordingly.
Two additional concetps:
- Compaction: Cassandra will run compaction to consolidate data into a smaller set of SSTables.
- SSTable Indexing: Cassadra stores files that serve as indices to SSTables on disk, to support faster retrieval of data on-disk.
Gossip
Cassandra nodes communicate information throughout the cluster via “gossip”.
Fault Tolerance
Cassandra leverages a Phi Accrual Failure Detector technique to dedtect failure during gossip.
Hinted handoffs (for writes):
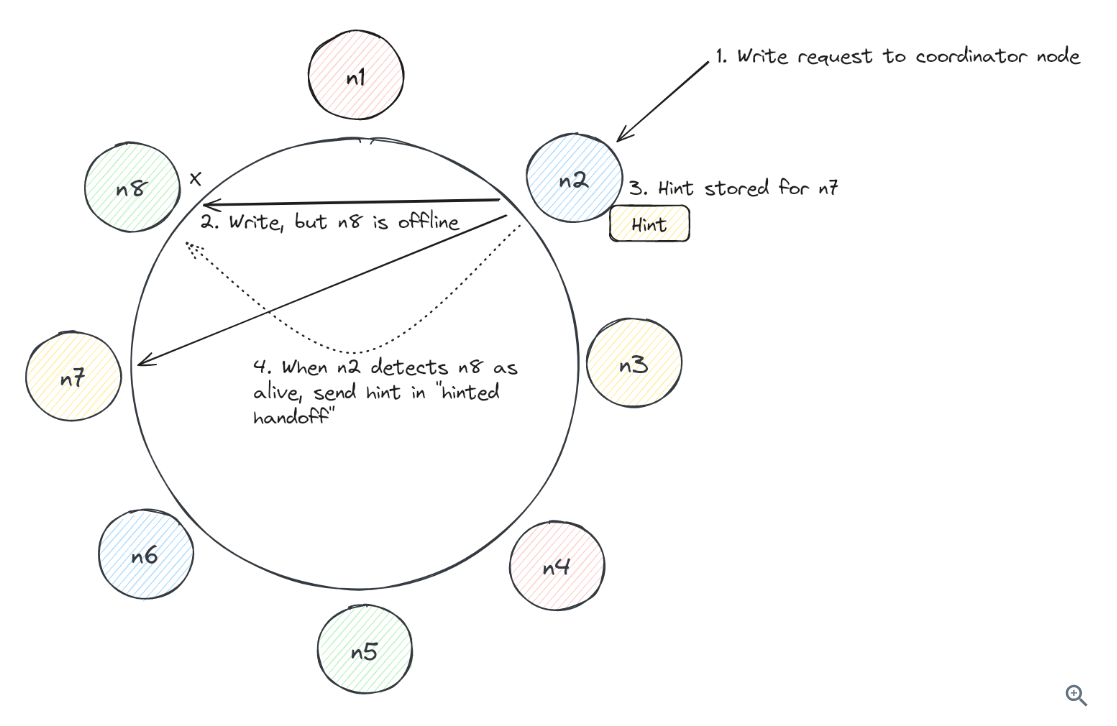
To scale Cassandra, consider:
- Partition Key
- Partition Size
- Clustering Key
- Data Denormalization
Several advanced features:
- Storage Attached Indexes (SAI): Offers global secondary indexes on columns.
- Materialized Views: A way for a user to configure Cassandra to materialize tables based off a source table.
- Search Indexing: Cassandra can be wired up to a distributed search engine such as ElasticSearch or Apache Solr.
Cassandra is a great choice in systems that prioritize availability over consistency and have scalability needs.
Cassandra is an especially good choice for systems with high write throughput, given its write-optimized storage layer based on LSM tree indexing.
Cassandra isn’t good for designs that prioritize strict consistency.
DynamoDB
DynamoDB is a fully-managed, highly scalable, key-value service provided by AWS:
- Fully-Managed: AWS takes care of all the operational aspects of the database, such as hardware provisioning, configuration, patching, and scaling.
- Highly Scalable: DynamoDB can handle massive amounts of data and traffic. It automatically scales up or down to adjust to the application’s need, without any downtime or performance degradation.
- Key-Value: DynamoDB is a NoSQL database.
Data Model
- Tables: Serve as the top-level data structure in DynamoDB, each defined by a mandatory primary key that uniquely identifies its items.
- Items: Correspond to rows in a relational database and contain a collection of attributes. Each item must have a primary key and can contain up to 400KB of data, including all its attributes.
- Attributes: Key-value paris that constitute the data within an item
DynamoDB is schema-less, providing high flexibility but requires careful data validation at the application level.
A user table in DynamoDB looks like:
1 | { |
DynamoDB tables are defined by a primary key, consiting of:
- Partition Key: Used to determine the physical location (partition) of the item within the database.
- Sort Key (optional): Used to order items with the same partition key value, enabling efficient range queries and sorting within a partition
Choose a good partition key to ensure data is evenly distributed across partitions.
Choose a good sort key in case you need to perform range queries or sorting.
DynamoDB uses a combination of consistent hashing and B-trees to efficiently manage data distribution and retrieva.
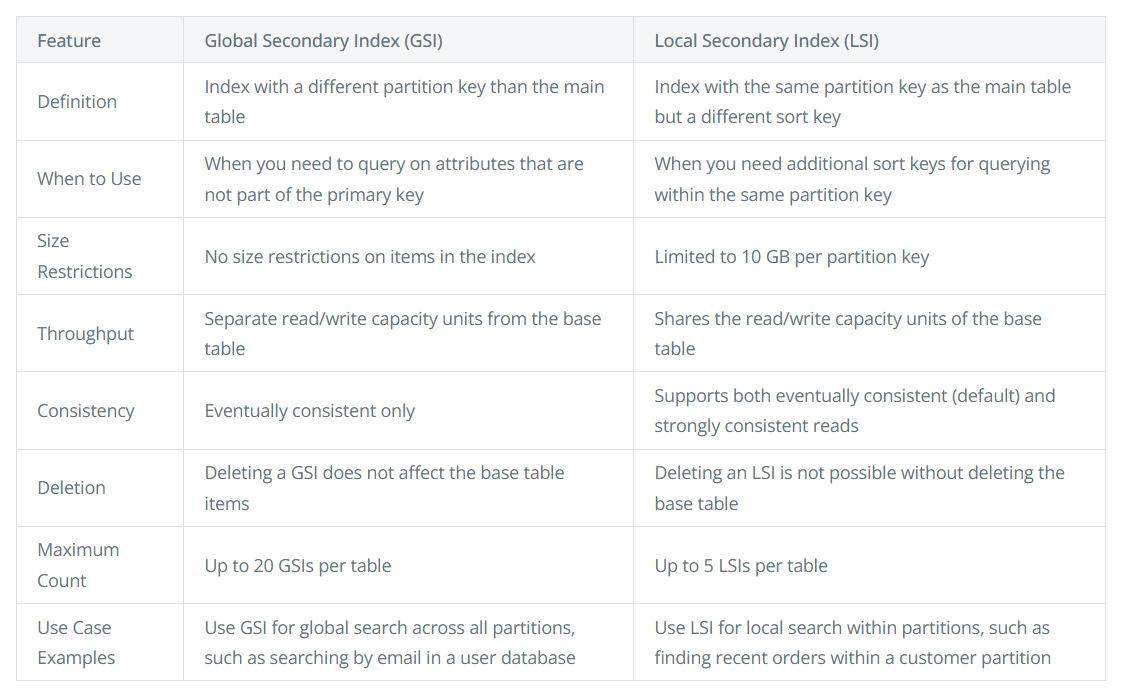
Secondary indexes:
- Global Secondary Indexes (GSI): An index with a partition key and optional sort key that differs from the table’s partition key. GSIs allow you to query items based on attributes other than the table’s partition key. Since GSIs maintain their own separate partitions and replicas, additional storage and processing overhead are required.
- Local Secondary Index (LSI): An indedx with the same partition key as the table’s primary key but a different sort key. LSIs enable range queries and sorting within a partition. LSIs can leverage local storage with the base table items.
Accessing Data
- Scan Operation: Reads every item in a table or index and returns the results in a paginated response. Useful when you need to read all items in a table or index, but inefficient for large datasets due to the need to read every item and should be avoided if possible.
- Query Operation: Retrieves items based on the primary key or secondary index key attributes. More efficient than scans.
Consistency Mode
DynamoDB can be configured to support two different consistency models: eventual consistency and strong consistency.
- Eventual Consistency: The default consistency model in DynamoDB. It provides the highest availability and lowest latency, but it can result in stale reads. With this configuration, DynamoDB is an AP system displaying BASE properties.
- Strong Consistency: This model ensures that all reads reflect the most recent write. This comes at the cost of higher latency and potentially lower availability. With this configuration, DynamoDB is a CP system displaying ACID properties.
DynamoDB has built-in support for Change Data Capture through DynamoDB streams, which allows:
- Consistency with ElasticSearch: DynamoDB streams can be used to keep an ElasticSearch indexe in sync with a DynamoDB table.
- Real-time Analytics: As the name suggests, basic functionality of streams.
- Change Notifications: We canuse DynamoDB streams to trigger Lambda functions in response to changes in database.