Note: The project repo is held private according to the course requirements. If you really want the code, please contact me via my email.
Content
- Specification
- Task 1 - Page Layouts
- Task 2 - Hash Table Implementation
- Task 3 - Concurrency Control
- Testing
- Formatting
- Debugging
- Gradescope
- Useful Links
- Known Issues
Specification
BusTub DBMS is used as the skeleton code. In this project, a disk-backed hash table is implemented based on extendible hashing scheme which is a form of dynamic hashing schemes. The hash table index is responsible for fast data retrieval without having to do full scan of a table.
The index comprises a directory page that contains pointers (page Ids) to bucket pages. The table will access pages through the buffer pool that is implemeted in Project #1. The hash table supports bucket splitting/merging for full/empty buckets, and directory expansion/contraction for when the global depth must change.
The implementation is thread-safe. Multiple threads can access the internal hash table data structures simultaneously and concurrency control is properly handled.
The following components in the storage manager are implemented in this project:
- Page Layouts
- Extendible Hashing Implementation
- Concurrency Control
Task 1 - Page Layouts
The hash table should be stored in disk pages and be accessed through DBMS’s BufferPoolManager
Two Page classes are implemented to store the data of the hash table
Hash Table Directory Page
This class holds all of the metadata for the hash table. Fields are listed below:
page_id_: Self Page Idlsn_: Log sequence numberglobal_depth_: Global depth of the directorylocal_depths_: Array of local depths for each bucketbucket_page_ids_: Array of bucketpage_id_t
It is implemented within the following two files:
src/include/storage/page/hash_table_directory_page.hsrc/storage/page/hash_table_directory_page.cpp
Note: local_depth_ and global_depth_ are declared to be different types, one is uint8_t, the other is uint32_t. I think it is not typo, it just memory alignment within a page.
GetSplitImageIndex: Serves for the purpose of fetching a bucket when local depth increases. For example, if a bucket has an index ofbucket_page_id = 0101, with its local depth 3 and a global index 4, then its ‘split image hasbucket_page_id = 1101
Hash Table Bucket Page
Three arrays:
occupied_: The ith bit of is 1 if the ith index ofarray_has ever been occupiedreadable_: The ith bit it 1 if the ith index ofarray_holds a readable valuearray_: The array that holds the key-value pairs
Fixed-length keys and values are supported (within a single hash table instance). It is still possible that key/value lengths are different across different hash table instance.
Insertion will find the first available slot to insert a record if there is no duplicate KV pairs
Deletion of a KV pair within a bucket page is implemented using a lazy approach. The memory/disk space is not released. The corresponding bit in readable_ array is reset instead.
It is implemented within the following two files:
src/include/storage/page/hash_table_bucket_page.hsrc/storage/page/hash_table_bucket_page.cpp
Note: occupied_ array is used to keep track of the currently used KV pair slots. It is non-decreasing when the program is executing. Besides, the index can be built on non-unique keys, so KV pairs with the same key and different values are allowed to be stored in the same hash index table.
Task 2 - Hash Table Implementation
In this part, a hash table based on the extendible hashing scheme is implemented. The hash function used is MurmurHash3_x64_128, which ideally can generate uniformly distributed hash values in the key space. There is downcast conversion from 64-bit to 32-bit hash in our implementation. The hash table index supports both unique and non-unique keys. Although normally we prefer building index on top of unique keys. It is still essential for database engine to support non-unique key index.
The implementation uses generic types which can supports KV pairs of different types, declared as:
1 | template <typename KeyType, typename ValueType, typename KeyComparator> |
Explanations for generic types:
KeyType: The type of key in the hash table. Key type (of fixed length) must be consistent across a single hash table, as is usually seen in a database index scheme. It is the type of the actual index attribute.ValueType: It is a 64-bit RID which is used to uniquely identify a single record within a table. Equality test for Instances of this type can done using the==operator.KeyComparator: Used to compare whether twoKeyTypeinstances are less/greater-than each other
The following APIs are supported by the hash table:
Insert: Insert a KV pair into the hash table directory and the corresponding bucket. The method fails if attemptingto insert an existing KV pair.GetValue: Perform point search, non-unique index key is supported. So the hash table allows multiple KV pairs with the same key and different valuesRemove: Delete a KV pair from the hash table.
The implementation supports bucket splitting/merging and directory growing/shrinking on insertions and deletions.
Directory Indexing
We use the convention of least-significant bits on hashing. It is worth noticing that the textbook Database System Concepts uses the convention of most-significant bits. Both implementations are correct. But the least-significant bits convention makes the directory expansion operation much simpler. So I choose to implement it instead.
Splitting Buckets
When the target bucket for insertion is full, then it must be split to make room for the new KV pair. Bucket splits are only invoked when an insertion would overflow a page. It should notice that sometimes splitting once may not be necessary if the insertion still overflows a page after splitting. So splitting should be done recursively.
Merging Buckets
Merging should be attempted when a bucket becomes empty. Several rules for bucket merging are provided below:
- Only empty buckets can be merged
- Buckets can only be merged with their split image if their split image has the same local depth and two images to be merged can fit into a single one
- Buckets can only be merged if their local depth is greater than 0
Directory Growing
When buckets split happens, we should also check whether directory growing is necessary or not.
Directory Shrinking
First we should notice: Given that the global depth of the hash table is gdepth and local depth of a bucket ldepth. Then the number of entries in the hash table directory pointing to the bucket can be written as:
$$
2^{\text{gdepth} - \text{ldepth}}
$$
It tells us that if the local depth of every bucket is strictly less than the global depth of the hash table directory. Then we don’t necessary so many entries in the directory thus it can shrink.
It is implemented within the following two files:
src/include/container/hash/extendible_probe_hash_table.hsrc/container/hash/extendible_probe_hash_table.cpp
Insertion Implementation Details
When we attempt to insert a new KV pair into the extendible hash table. There are several situations:
- When the target bucket for insertion is not full. We only need to insert the KV pair into the bucket.
- When the target bucket for insertion is full. There are two possibilities in this case:
- If the
local_depthof the target page is strictly less than theglobal_depthof the hash table, meaning that there are multiple entries in the directory page pointing to the target bucket page. Then in the first round, we attempt to split the bucket into two buckets (one is the old one, one is the new one), and modify the directory entries in the hash table so that half of the previousbucket_page_idsthat refer to the old bucket page now refer to the new split image. And the other half are left as they are. Then we redistribute all the existing KV pairs in the old bucket page into the old one and the split image. By doing this we try to make some room for the new KV pair. However, although it rare, it is still possible that the new target bucket (either the old one or the new one) is still full and we need to do further adjustment. So we callInsertrecursively. - If the
local_depthof the target page is equal to theglobal_depthof the hash table, meaning that there is only one entry in the directory page pointing to the target bucket page. In order to insert a new KV pair, we have to double the size of the directory page and increment the global depth. Before that, we should make sure that the size of the directory after expanding does not exceed the maximum, which is defined as a macroDIRECTORY_ARRAY_SIZEin the filesrc/include/storage/page/hash_table_page_defs.h, in our implementation, the number is 512. Same as the previous situation, after doubling the size of the directory, we modify the entries, redistribute the old KV pairs in the old bucket page, and callInsertrecursively, until either the insertion succeeds or the maximum directory size is reached.
- If the
Deletion Implementation Details
When we want to delete a KV pair from a bucket. There are several situations:
- When the target page is not empty after deletion. We only need to delete the KV pair and return.
- When the target page becomes empty after deletion. We attempt a
Mergeoperation:- If either the target bucket has a different same local depth from its split image or the local depth is 0. We do not merge and return.
- Otherwise, we merge the target bucket with its split image, modifies the directory page entries and decrement the local depth. Delete the target bucket page from the buffer pool. Finally we check whether the directory can shrink. If it can, we shrink down the directory size by a factor of 2. The condition for determining whether the directory can shrink is: the local depth of every bucket is strictly less than the global depth of the directory. We need to notice that
Shrinkshould be a recursive call whileMergeis not, that is becauseMergeoperation will only be invoked once a new KV pair is deleted from the hash table, based on our setting and assumptions.
Note: The transaction which appears in many function declarations are used for transaction management in a later project. It is not used in this project and should be left as is and passed along to other function calls if necessary. Besides, please do not add any additional attributes to the HashTableBucketPage because its design to fit into a 4 KB page in the buffer pool. If you add additional attributes, its memory region may overlap with other pages as you add more and more KV pairs into a bucket page. We don’t need unique identifiers (bucket_page_id) within a bucket page. We use the array bucket_page_ids_ in the directory page to keep track of the page number for each bucket page. In other words, The bucket page only needs to maintain KV pairs and two bitmaps which keep track of the memory usage. For the same reason, we should also not add any additional attribute into the HashTableDirectoryPage class.
Task 3 - Concurrency Control
The previous implementation only supported single-threaded execution. In this final part, we modify the implementation so that it supports multiple threads reading/writing the hash table at the same time.
We use read/write latches to protect the whole hash table page and buckets. The latch class is defined in src/include/common/rwlatch.h. It provides two latching modes:
- Write Mode: excludes all concurrent reads and writes
- Read Mode: allows concurrent reads, excludes all concurrent writes
To implement concurrency control for the extendible hash table scheme, we apply the following rules:
GetValue: Apply a read latch on the hash table and a read latch on the target bucket pageInsert: Apply a read latch on the hash table directory and a write latch on the target bucket pageSplitInsert: Apply a write latch on the hash table, preventing other threads from accessing the hash tableRemove: Apply a read latch on the hash table and a write latch on the target pageMerge: Apply a write latch on the hash table, preventing other threads from accessing the hash table
**Note: **
- Before the call to
SplitInsert, remember not to release any read/write latches in order not to have any concurrency issues - Remember to release the read/write latch before the next call to
Insertin order to avoid dead lock situation - Concurrency control for read/write lock is much harder than mutex lock. Need to pay special attention to each critical section while not degrading the system performance
- Remember to
Unpinany pages that are used immediately - Do not lock/unlock across different functions, which may degrade the concurrency performance
- When the
SplitInserthappens when the directory page becomes full and all the target bucket becomes full. In a concurrent scenario (in a single thread situation, always choose the first option, otherwise there will be an infinite loop), we have to make a decision (in my implementation I choose the first one):- Either return
falseinSplitInsert, indicating that the current insertion fails - Or put the current the thread into sleep for some duration, and attempt to call
Insertagain (in the case that we hope other threads acquire the write lock and delete some KV pairs in the target bucket)
- Either return
- For the
MergeAPI, scan through all the buckets to see whether any other merges are needed. In the function call toRemove, it is possible that more than two buckets become empty beforeMergein any threads acquire the write lock - If a write latch is applied on the whole hash table, then don’t need to apply further read/write latches on other pages because the whole hash table becomes inaccessible for other threads under a write latch
Testing
GTest is used to test each individual components of the assignment. The test files for this assignment locate in:
HashTableBucketPage:test/container/hash_table_page_test.cppHashTableDirectoryPage:test/container/hash_table_page_test.cppExtendibleHashTable:test/container/hash_table_test.cpp
Compile and run each test individually by:
1 | # take LRUReplacer test for example |
Or use make check-tests to run all of the test cases. Disable tests in GTest by adding DISABLE_ prefix to the test name.
Note: Local unit tests will not test the concurrency capability of the system.
Formatting
The code is compliant with Google C++ Style Guide.
To lint, run the following commands:
1 | $ make -j format |
Debugging
Instead of using printf, logging the output using LOG_* macros:
1 | LOG_INFO("# Pages: %d", num_pages); |
To enable logging, do the following configuration:
1 | $ mkdir build |
Add #include "common/logger.h" to any file in which you want to make use of the logging infrastructure.
Gradescope
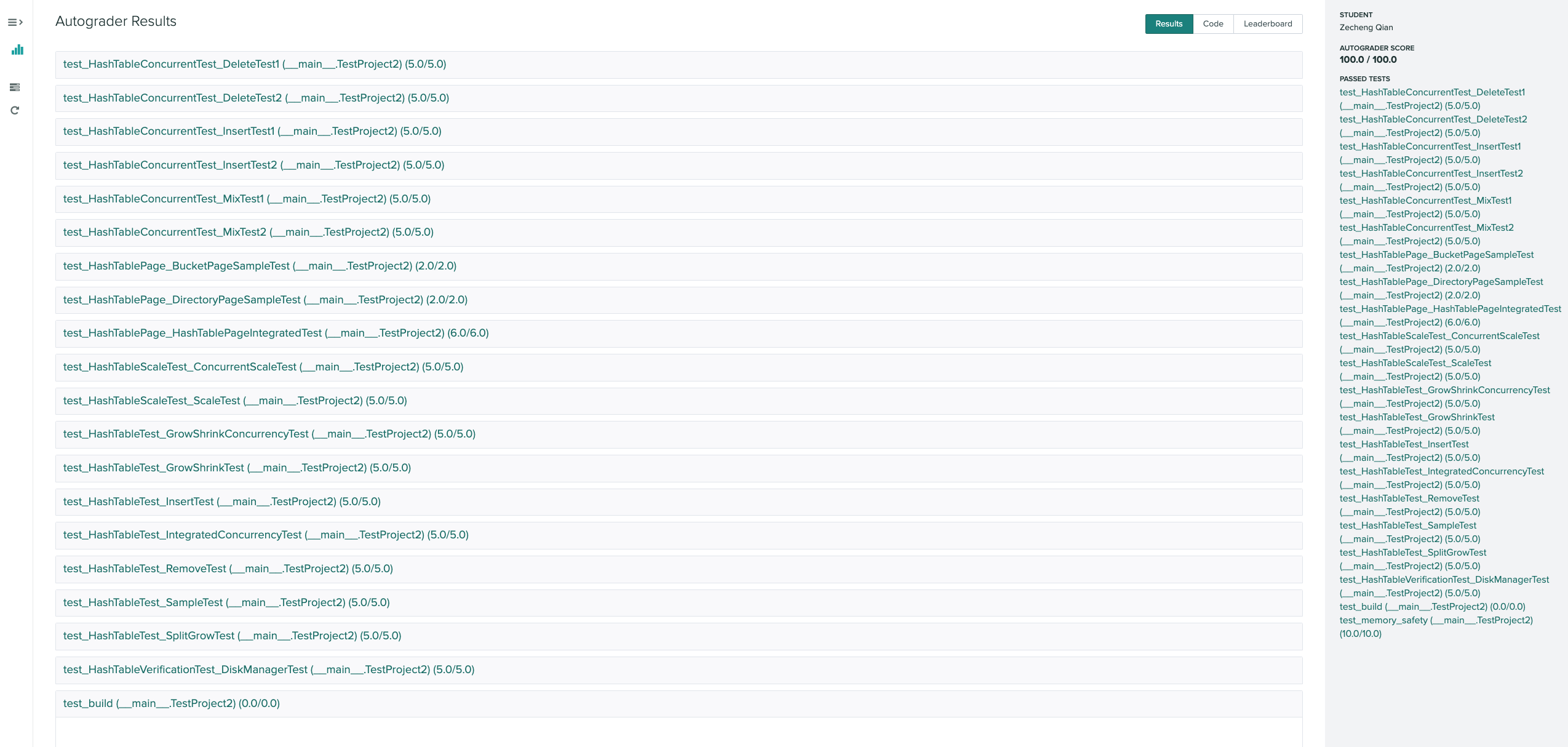
Useful Links
CMU-15445 2021 Project 2-Extendible Hash Index (the most useful one for concurrency control)
Known Issues
Not found yet